Dqn Pseudocode

Multi Agent Reinforcement Learning In Beer Distribution Game Laptrinhx

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Deep Reinforcement Learning

Deep Reinforcement Learning

Deep Reinforcement Learning

Deep Q Learning With Tensorflow 2 By Aniket Gupta Medium
Here, our update is the same as that of vanilla gradient descent.

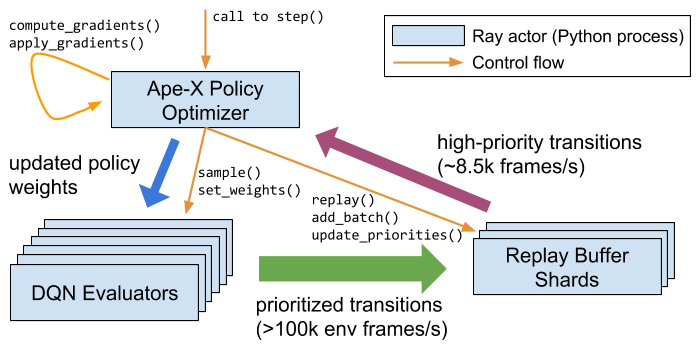
Dqn pseudocode. The voltage (V) between the poles of a conductor is equal to the product of the current (I) passing through the conductor and the resistance (R) present on the conductor.It’s demonstrated by the V = I * R formula. 15 Tabular TD(lambda), accumulating traces p. In Figure 2(a) below, we categorize the vanilla DQN pseudocode into lines for control logic (orange), sampling (green), replay (violet), and gradient-based optimization (blue).
A DQN agent is a value-based reinforcement learning agent that trains a critic to estimate the return or future rewards. Deep-Q-Learning-Paper-To-Code / DQN / preprocess_pseudocode Go to file Go to file T;. Pseudocode is a method of planning which enables the programmer to plan without worrying about syntax.
This interaction can be seen in the diagram below:. Write pseudo code to print all multiples of 5 between 1 and 100 (including both 1 and 100). Algorithms can be presented by natural languages, pseudocode, and flowcharts, etc.
2.3 Deep Q Network (DQN). Get initial state s 3:. Pseudocode is an informal program description that does not contain code syntax or underlying technology considerations.
Write pseudo code that will perform the following. To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task:. Q-learning is a model-free reinforcement learning algorithm to learn quality of actions telling an agent what action to take under what circumstances.
Introduction to reinforcement learning. Writing code can be a difficult and complex process. The book, as the title suggests, describes a number of algorithms.
Two important ingredients of the DQN algorithm as. Write a program that asks the user for a temperature in Fahrenheit and prints out the same temperature in Celsius. Remember that Q-values correspond to how good it is to be at that state and taking an action at that state Q(s,a).
With probability "select a random action a 7:. 2 Pseudocode for DQN Teacher {algorithm} h! \KwData Training dataset organised into N batches of Mahalanobis curriculum initialise teacher network, g initialise target teacher by copying predictor teacher, g T select value of frequency of target network update and batchsize of replay data, M. Sometimes, breaking down a multilayered problem into smaller, easily digestible steps is a helpful way t.
Next we discuss core RL elements, including value function, in particular, Deep Q-Network (DQN), policy, reward, model, planning, and. By contrast, Q-learning has no constraint over the next action, as long as it maximizes the Q-value for the next state. Jika B>A dan B>C maka B paling besar 4.
Are the Q-values accurate?. But we introduce a new term called velocity, which considers the previous update and a constant which is called momentum. Maka C paling kecil/terkecil.
10 Policy iteration p. Go to line L;. Deep Q-Network (DQN)-II Experience Replay and Target Networks.
Namun dibuat sesederhana mungkin sehingga tidak akan ada kesulitan bagi pembaca untuk memahami algoritma-algoritma dalam buku ini walaupun pembaca belum pernah mempelajari bahasa Pascal. DQN updates the Q-value function of a state for a specific action only. Algorithm 1 Asynchronous DQN - pseudocode Pseudocode for each slave node.
We start with background of machine learning, deep learning and reinforcement learning. We give an overview of recent exciting achievements of deep reinforcement learning (RL). Reinforcement Learning (RL) Tutorial.
It's much easier for DQN to learn to play control/instant action games like Pong or Breakout but doesn't do well on games that need some amount of planning (Pacman, for example). Contoh Pseudocode – Pseudocode adalah bagian dari algoritma yang bertujuan untuk memahami alur logika dari suatu program. Dqn.test(env, nb_episodes=5, visualize=True) This will be the output of our model:.
Choose a scenario randomly from the training set as the environment for current episode 6:. Pseudocode is an artificial and informal language that helps programmers develop algorithms. Browse other questions tagged reinforcement-learning q-learning dqn deep-rl pseudocode or ask your own question.
Di postingan contoh Pseudocode dan Flowchart nya. With algorithms, we can easily understand a program. Terdapat tiga algoritma yang biasa digunakan, yaitu bahasa natural, pseudocode dan flowchart.
1 contributor Users who have contributed to this file 75. We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. Therefore, SARSA is an on-policy algorithm.
DQN pseudocode Algorithm 1 DQN initialize for Q ,set ¯ – for each step do if new episode, reset to s 0 observe current state s t take -greedy action a t based on Q ps t, ¨q ⇡pa t |s t q“ # 1 ´ |A|´1 |A| a t “ argmax a Q ps t,aq 1 |A| otherwise get reward r t and observe next state s t`1 add ps t,a t,r t,s t`1 q to replay buffer D. Masukkan bilangan A,B,C 2. Kamu bisa belajar dari 21 Contoh Algoritma dan Flowchart pemrograman yang simpel dan sangat mudah dipelajari.
Several improvements have been proposed since the. But PG is a classification problem so we use log likelihood or cross. What is the algorithm of the program that calculates the voltage between the poles of the conductor by using the formula according to the current and.
X = Convert X to Celsius. Remember that pseudocode is subjective and nonstandard. Dueling DQN updates V which other Q(s, a’) updates can take advantage of also.
We almost always get chatters around near optimal value functions. There are many RL tutorials, courses, papers in the internet. 10 Tabular TD(0) p.
If Model output is selected then. Pseudocode summarizes a program’s steps (or flow) but excludes underlying implementation details. We can summarize the previous explanations with this pseudocode for the basic DQN algorithm that will guide our implementation of the algorithm:.
Try this amazing Pseudocode Test:. There is no set syntax that you absolutely must use for pseudocode, but it is a common professional courtesy to use standard pseudocode structures that other programmers can easily understand. Dqn.fit(env, nb_steps=5000, visualize=True, verbose=2) Test our reinforcement learning model:.
As predicted Q increases, so does the return. It does not require a model (hence the connotation "model-free") of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. As stated above, reinforcement learning comprises of a few fundamental entities or concepts.
Process 1 and process 3 run at the same speed, process 2 is slow •Fitted Q-iteration:. Pseudocode of the DQN model and a specific structure thereof are illustrated in Fig. DQN is a variant of Q-learning.
A flowchart is the graphical or pictorial representation of an algorithm with the help of different symbols, shapes, and arrows to demonstrate a process or a program. For an experimental study of the contribution of each mechanism and the corresponding Rainbow DQN network, using in addition distributional learning, see Section 4.7.1). For an n-dimensional state space and an action space contain-ing mactions, the neural network is a function from Rnto Rm.
Pseudocode yang ditulis di dalam buku ini akan menyerupai (meniru) syntax-syntax dalam bahasa Pascal. Simply, we can say that it’s the cooked up representation of an algorithm. Bahasa natural merupakan sebuah ururtan atau langkah-langkah untuk memecahkan suatu permasalahan dengan menggunakan bahasa sederhana yang biasa digunakan sehari-hari (menggunakan.
Latest commit cb793a8 Nov , 19 History. Initially, feed stream data including feed flowrate and feed mass ratio from the LHS and the expected API concentration value computed by MC simulation runs are imported to the DQN model. For more information on Q-learning, see Q-Learning Agents.
B) Calculate the average of the five numbers. Also explore over 301 similar quizzes in this category. For algorithms whose names are boldfaced a pseudocode is also given.
12 Every-visit Monte-Carlo p. A deep Q network (DQN) is a multi-layered neural network that for a given state soutputs a vector of action values Q(s;;. We apply our method to seven Atari 2600 games from the Arcade.
We will also present in detail the code that solves the OpenAI Gym Pong game using the DQN network introduced. A) Read in 5 separate numbers. OpenAI gym provides several environments fusing DQN on Atari games.
Process 3 in the inner loop of process 2, which is in the inner loop of process 1. DQNAgent rl.agents.dqn.DQNAgent(model, policy=None, test_policy=None, enable_double_dqn=True, enable_dueling_network=False, dueling_type='avg') Write me. Update = learning_rate * gradient velocity = previous_update * momentum parameter = parameter + velocity – update.
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. These are the following. It can be proven that given sufficient training under any -soft policy, the algorithm converges with probability 1 to a close approximation of the action-value function for an arbitrary target policy.Q-Learning learns the optimal policy even when actions are selected according to a more exploratory or even.
#create two networks and synchronize current_model, target_model = DQN(num_states, num_actions), DQN(num_states, num_actions) def update_model (current_model, target. The Algorithm Pseudocode The Problem Reinforcement learning is known to be unstable or even to diverge when a non-linear function approximator such as a neural network is used to represent the action-value function. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards.
Q-Learning is an Off-Policy algorithm for Temporal Difference learning. Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning. They must derive efficient.
We discuss six core elements, six important mechanisms, and twelve applications. So each Dueling DQN training iteration is. Jika A>B dan A>C maka A paling besar 3.
Write pseudo code that will count all the even numbers up to a user defined stopping point. This one summarizes all of the RL tutorials, RL courses, and some of the important RL papers including sample code of RL algorithms. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards.
Trivia quiz which has been attempted times by avid quiz takers. Double duelling DQN with prioritized replay was the state-of-the-art method for value-based deep RL (see Hessel et al. 48 is probably a difficult game for a simple Q-network to learn because it requires long-term planning.
It is a methodology that allows the programmer to represent the implementation of an algorithm. ), where are the parameters of the network. From the pseudo code above you may notice two action selection are performed, which always follows the current policy.
Buatlah algoritma menggunakan flowchart dan pseudocode untuk menginput 3 buah bilangan, kemudian tentukan bilangan terbesar, terkecil, dan rata-ratanya. So we can decompose Q(s,a) as the sum of:. This is the second post devoted to Deep Q-Network (DQN), in the “Deep Reinforcement Learning Explained” series, in which we will analyse some challenges that appear when we apply Deep Learning to Reinforcement Learning.
Implementation Dueling DQN (aka DDQN) Theory. Copy path philtabor deep q learning in the atari library. The theory of reinforcement learning provides a normative account deeply rooted in psychological and neuroscientific perspectives on animal behaviour, of how agents may optimize their control of an environment.
Congratulations on building your very first deep Q-learning model. Pseudocode is an informal high-level description of the operating principle of a computer program or an algorithm For example, a print is a function in python to display the content whereas it is System.out.println in case of java, but as pseudocode display/output is the word which covers both the programming languages. Featured on Meta Responding to the Lavender Letter and commitments moving forward.
Pseudocode is a "text-based" detail (algorithmic) design tool. Initialize process update counter t= 0 2:. 17 First-visit Monte-Carlo p.
An environment which produces a state and reward, and an agent which performs actions in the given environment. Artikel contoh Pseudocode dan Flowchart nya ini dipublish oleh jefry D HighWind pada hari Jumat, 04 Oktober 13.Semoga artikel ini dapat bermanfaat.Terimakasih atas kunjungan Anda silahkan tinggalkan komentar.sudah ada 6 komentar:. Halo teman yang sedang belajar flowcart dan algoritma.
Pseudocode is a "text-based" detail (algorithmic) design tool. In the beginning, we need to create the main network and the target networks, and initialize an empty replay memory D. Pseudocode CSE 1321 Guide.
DQN is a regression problem so we have used L2 loss function as cost function and we minimize that loss during the training. In Figure 2(b), the Ape-X formulation of distributed DQN, these same components are still used, but are organized quite differently. The deep Q-network (DQN) algorithm is a model-free, online, off-policy reinforcement learning method.
Pseudo code is a term which is often used in programming and algorithm based fields.

Deep Sarsa Deep Q Learning Dqn
3

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Personalized Project Recommendations Using Reinforcement Learning Eurasip Journal On Wireless Communications And Networking Full Text

Task Scheduling Based On Deep Reinforcement Learning In A Cloud Manufacturing Environment Dong Concurrency And Computation Practice And Experience Wiley Online Library

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium

A Trust Aware Task Allocation Method Using Deep Q Learning For Uncertain Mobile Crowdsourcing Human Centric Computing And Information Sciences Full Text

Playing Cartpole With Natural Deep Reinforcement Learning Oliver Xu S Blog
Q Tbn 3aand9gctv9wou1ce01x5kqcf47vi Fienslmincq8fqjcji4g18goecla Usqp Cau

From Q Learning To Dqn

Distributional Bellman And The C51 Algorithm Felix Yu

Q Learning Wikipedia
Q Tbn 3aand9gctv9wou1ce01x5kqcf47vi Fienslmincq8fqjcji4g18goecla Usqp Cau

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Project

An Overdue Post On Alphastar Part 2

Deep Q Network Dqn Ii Experience Replay And Target Networks By Jordi Torres Ai Aug Towards Data Science

Rl Weekly 21 The Interplay Between Experience Replay And Model Based Rl Endtoend Ai

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Let S Make A Dqn Double Learning And Prioritized Experience Replay ヤロミル

Lei Mao S Log Book Making Reinforcement Learning Agent Library

Deep Reinforcement Learning Based Images Segmentation For Quantitative Analysis Of Gold Immunochromatographic Strip Sciencedirect

Policy Gradient Algorithms

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink

Deep Deterministic Policy Gradient Ddpg

Deep Q Learning Mc Ai

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
Arxiv Org Pdf 1701
Distributed Policy Optimizers For Scalable And Reproducible Deep Rl Rise Lab
Q Tbn 3aand9gct9nay65nz9jnygtqujzpt3wzpfmhjxi9hohz7mq0n28trmcynw Usqp Cau

Deep Reinforcement Learning Of How To Win At Battleship Ccri

Deep Reinforcement Learning In Strategic Board Game Environments Springerlink
Arxiv Org Pdf 1708

Twin Delayed Ddpg Spinning Up Documentation

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

A Brief Description Of Various Reinforcement Learning Algorithms A List Of Important Concepts And Terms Programmer Sought
Http Cs231n Stanford Edu Reports 17 Pdfs 616 Pdf

Dqn Qqdn And Dueling Dqn Formula Derivation Analysis Programmer Sought

Deep Reinforcement Learning With Hidden Layers On Future States Springerlink
2

Policy Gradient Algorithms
Deep Q Learning An Introduction To Deep Reinforcement Learning

Yad Neat Deep Reinforcement Learning An Overview About Pages Still Missing Topics But Good Stuff W Pointers T Co Aghih35zxi T Co Wtnrborfen

Reinforcement Learning 6 Temporal Difference Learning

Pdf Enhanced Model Free Deep Q Learning Based Control

Asynchronous Deep Reinforcement Learning From Pixels Dmitry Bobrenko S Blog

Deep Sarsa Deep Q Learning Dqn
Distributed Policy Optimizers For Scalable And Reproducible Deep Rl Rise Lab

Deep Deterministic Policy Gradient Spinning Up Documentation

Deep Rbf Value Functions For Continuous Control Deepai

Asynchronous Methods For Deep Reinforcement Learning The Morning Paper

Rl Reinforcement Learning Algorithms Quick Overview By Jonathan Hui Medium

Part 7 Deep Q Learning Data Machinist

Diving Deeper Into Reinforcement Learning With Q Learning
Curious Actor Critic Network Learning Always Works Best When You Get By D W Medium

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium

Deep Q Learning Part2 Double Deep Q Network Double Dqn By Amber Medium

Reinforcement Learning Dqn Related Knowledge And Code Implementation Programmer Sought

Deep Sarsa Deep Q Learning Dqn

Soft Actor Critic Spinning Up Documentation

Deep Sarsa Deep Q Learning Dqn

Policy Gradient Algorithms

Gym Experiments Cartpole With Dqn Voyage In Tech

A New Asynchronous Architecture For Tabular Reinforcement Learning Algorithms Springerlink

Mp4 Reinforcement Learning Principles Of Safe Autonomy Illinois University Of Illinois At Urbana Champaign

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Choose Function For On Policy Prediction With Approximation Stack Overflow
Dl Acm Org Ft Gateway Cfm Id Ftid 840 Dwn 1 Cfid Cftoken Ec87ea36 dd D199 4267 2aa7ab277be10f25

Deep Q Learning With Tensorflow 2 By Aniket Gupta Medium

Deep Reinforcement One Shot Learning For Artificially Intelligent Classification In Expert Aided Systems Sciencedirect

Distributed Policy Optimizers For Scalable And Reproducible Deep Rl Rise Lab

Rl Policy Gradient Algorithms
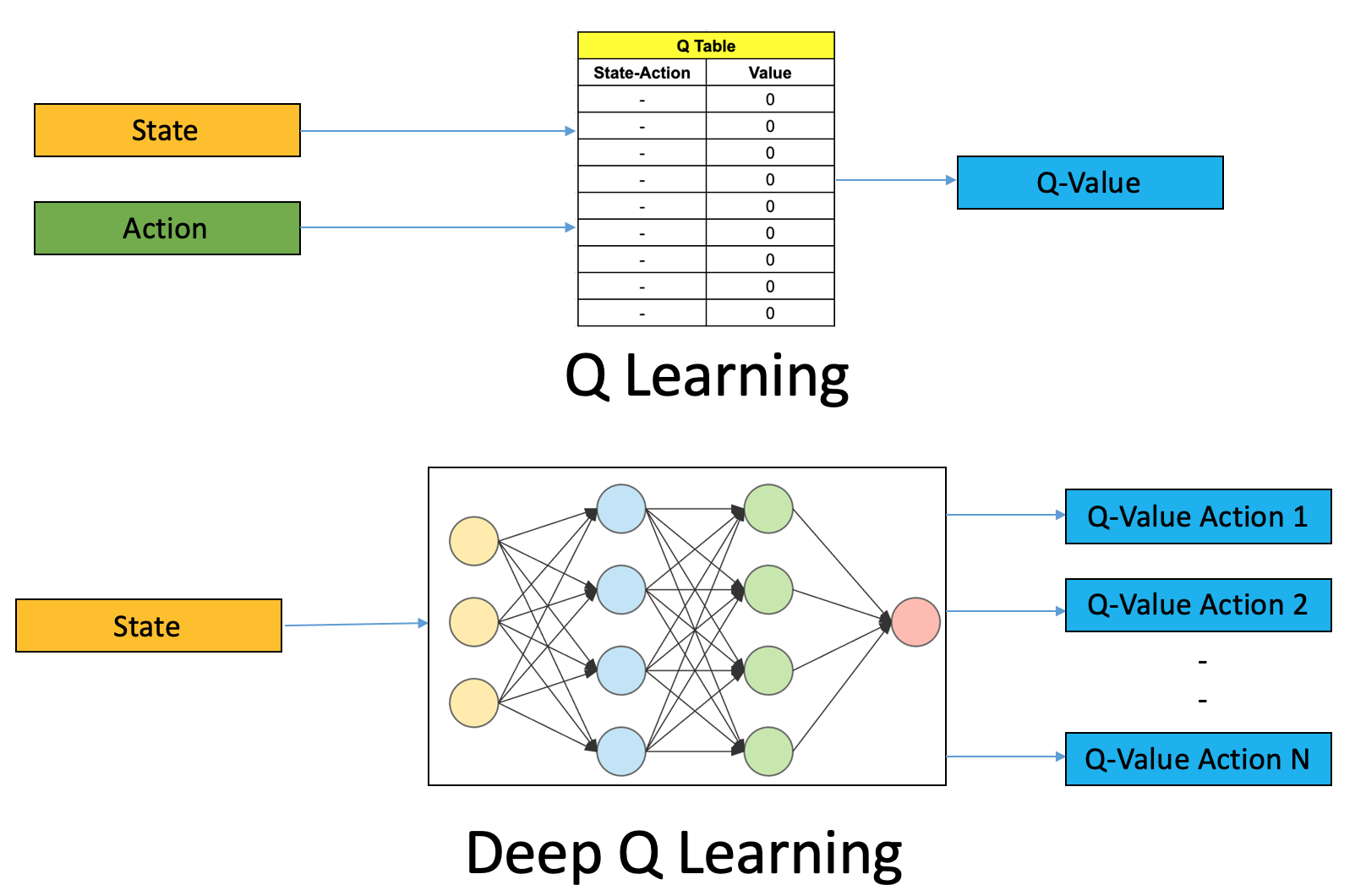
Deep Q Learning An Introduction To Deep Reinforcement Learning

Task Scheduling Based On Deep Reinforcement Learning In A Cloud Manufacturing Environment Dong Concurrency And Computation Practice And Experience Wiley Online Library

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Policy Gradient Algorithms

Double Q Reinforcement Learning In Tensorflow 2 Adventures In Machine Learning

Lei Mao S Log Book Making Reinforcement Learning Agent Library

Pdf A Review Of Reinforcement Learning For Autonomous Building Energy Management

What Is The Target Q Value In Dqns Artificial Intelligence Stack Exchange
Gradient Boosting In Crowd Ensembles For Q Learning Using Weight Sharing Springerlink

Figure 6 Using Deep Reinforcement Learning Approach For Solving The Multiple Sequence Alignment Problem Springerlink

Renom Rl Discrete c Renomrl 0 8 Documentation

Conquering Openai Retro Contest 2 Demystifying Rainbow Baseline By Flood Sung Intelligentunit Medium

Q Learning Wikipedia

Policy Gradient Algorithms

Noisy Dqn Programmer Sought

Task Scheduling Based On Deep Reinforcement Learning In A Cloud Manufacturing Environment Dong Concurrency And Computation Practice And Experience Wiley Online Library

Deep Q Learning Series Dqn Liao Yong Technology Space

A Reinforcement Learning Based System For Minimizing Cloud Storage Service Cost
People Eecs Berkeley Edu Pabbeel Nips Tutorial Policy Optimization Schulman Abbeel Pdf
ourses Berkeley Edu Files Download Download Frd 1

Goai 1 Asynchronous Methods For Deep Reinforcement Learning By Darrenyaoyao Medium

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink

Can Someone Please Explain The Target Update For Deep Q Learning Cross Validated



