Dqn Network Structure
Learn Reinforcement Learning 3 Dqn Improvement And Deep Sarsa Greentec S Blog

How To Match Deepmind S Deep Q Learning Score In Breakout By Fabio M Graetz Towards Data Science
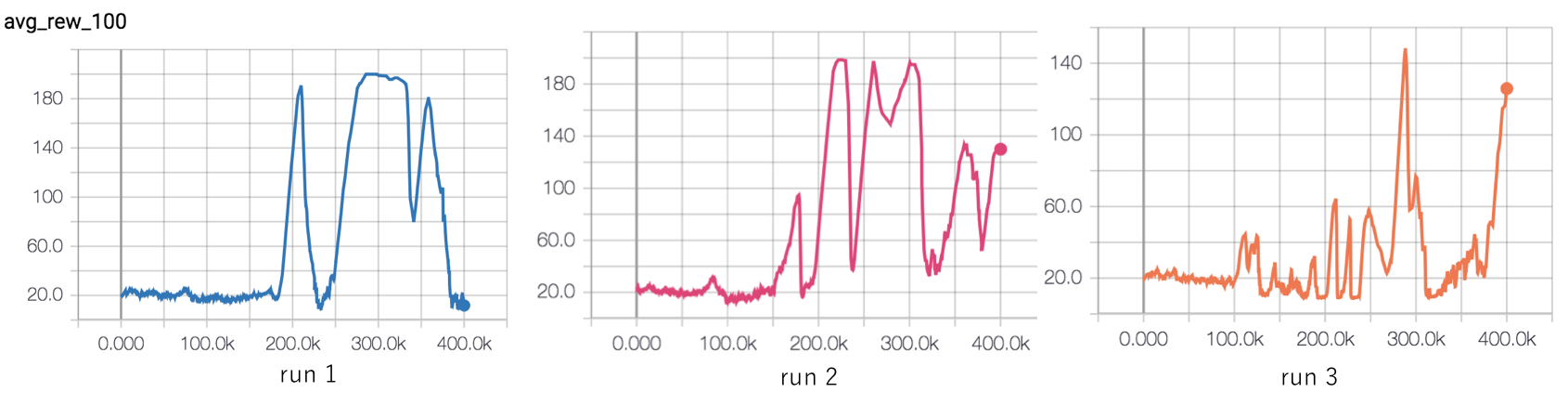
Ddqn Hyperparameter Tuning Using Open Ai Gym Cartpole The Intersection Of Energy And Machine Learning

Deep Reinforcement Learning Series 9 Dueling Dqn Ddqn Principle And Implementation Programmer Sought
Torch Dueling Deep Q Networks
Introduction To Double Deep Q Learning Ddqn Mc Ai
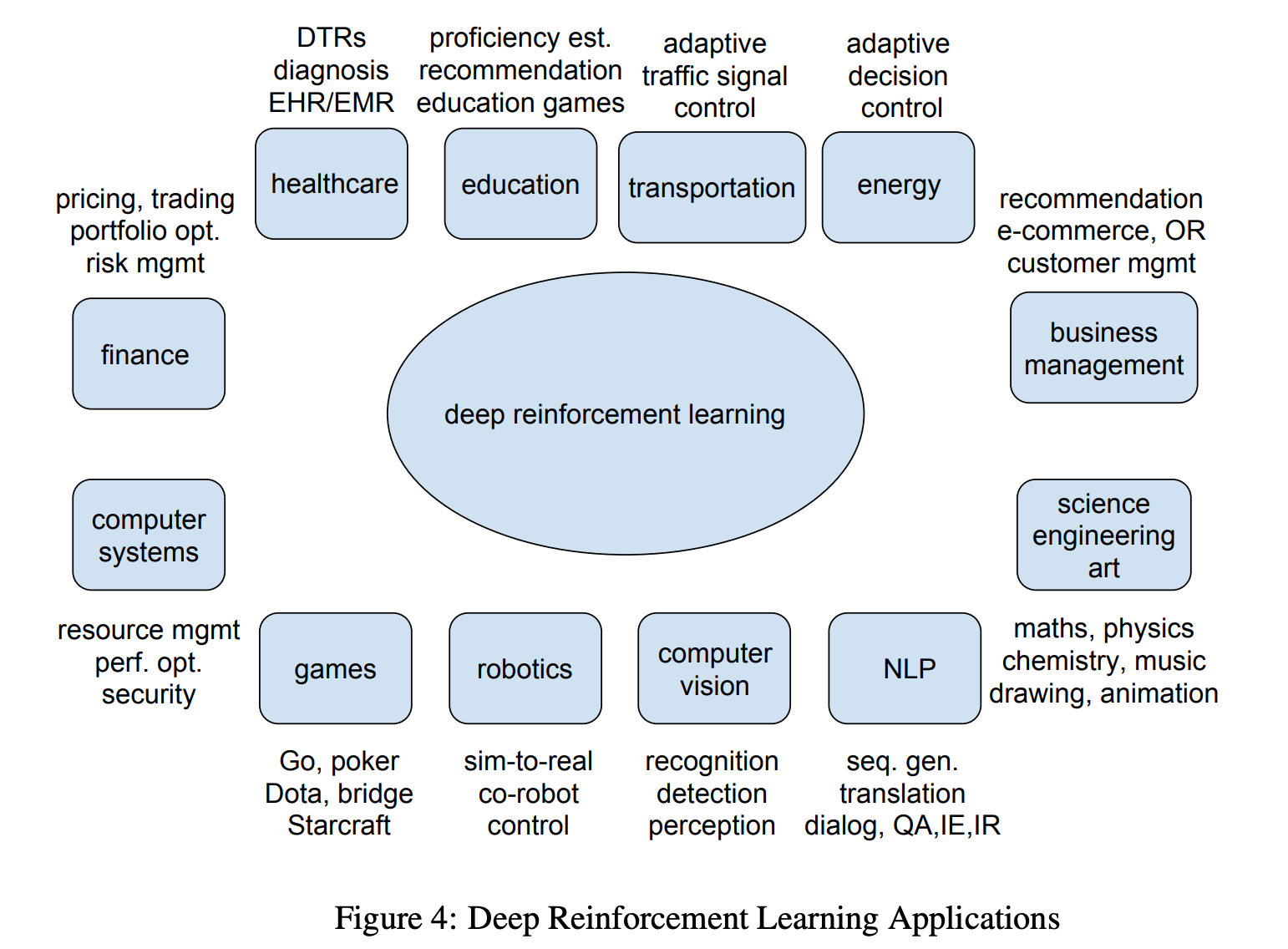
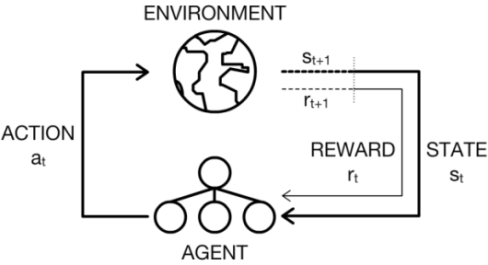
DeepMind applies DQN to Atari games, which is different from the previous practice, utilizing the video information as input and playing games against humans.
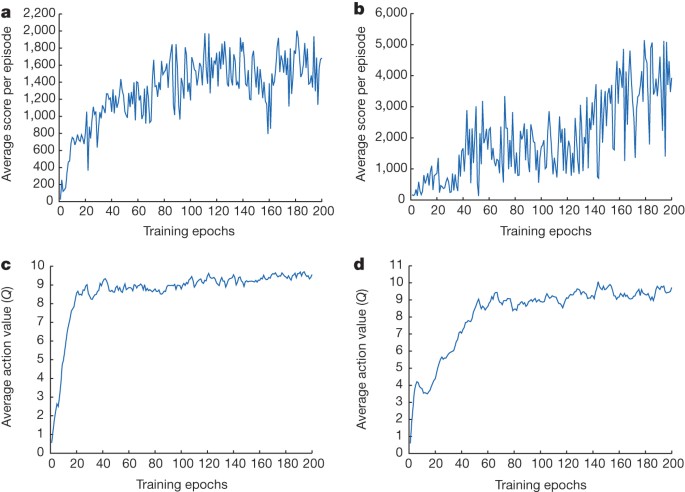
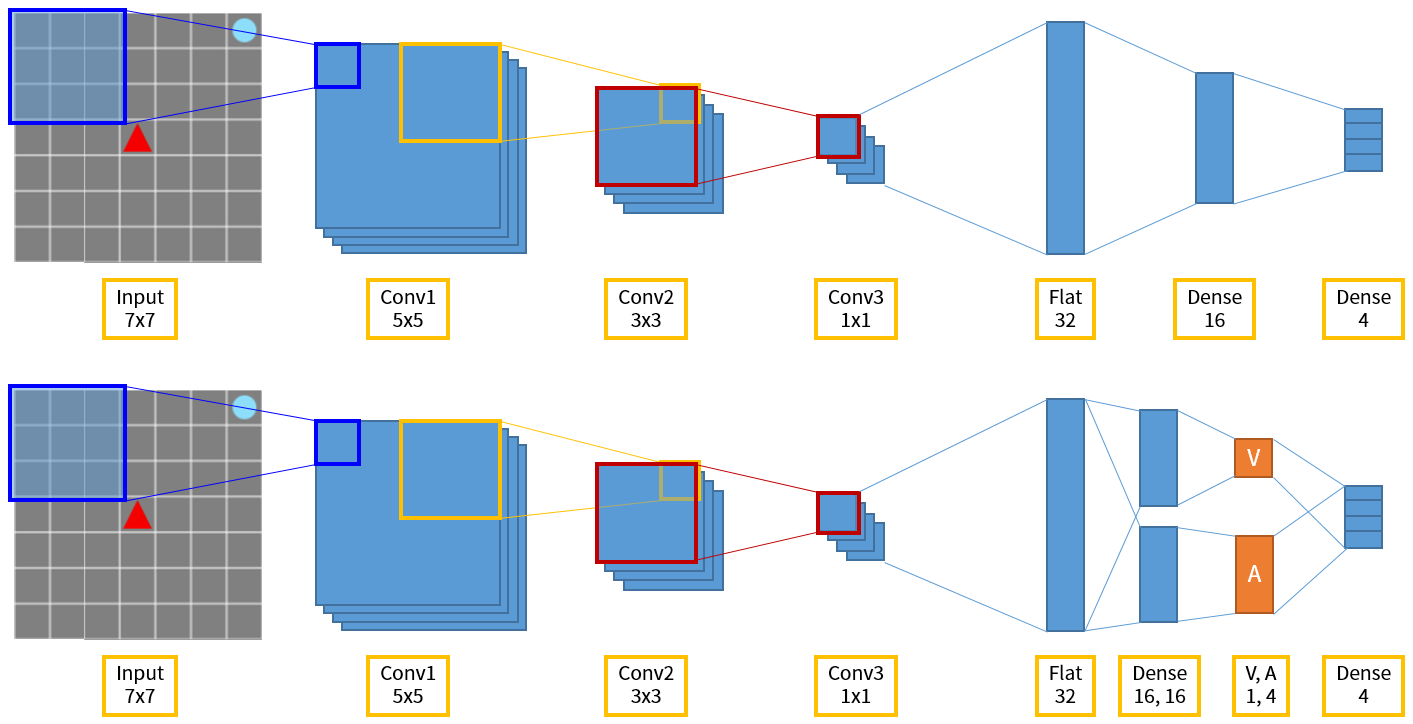
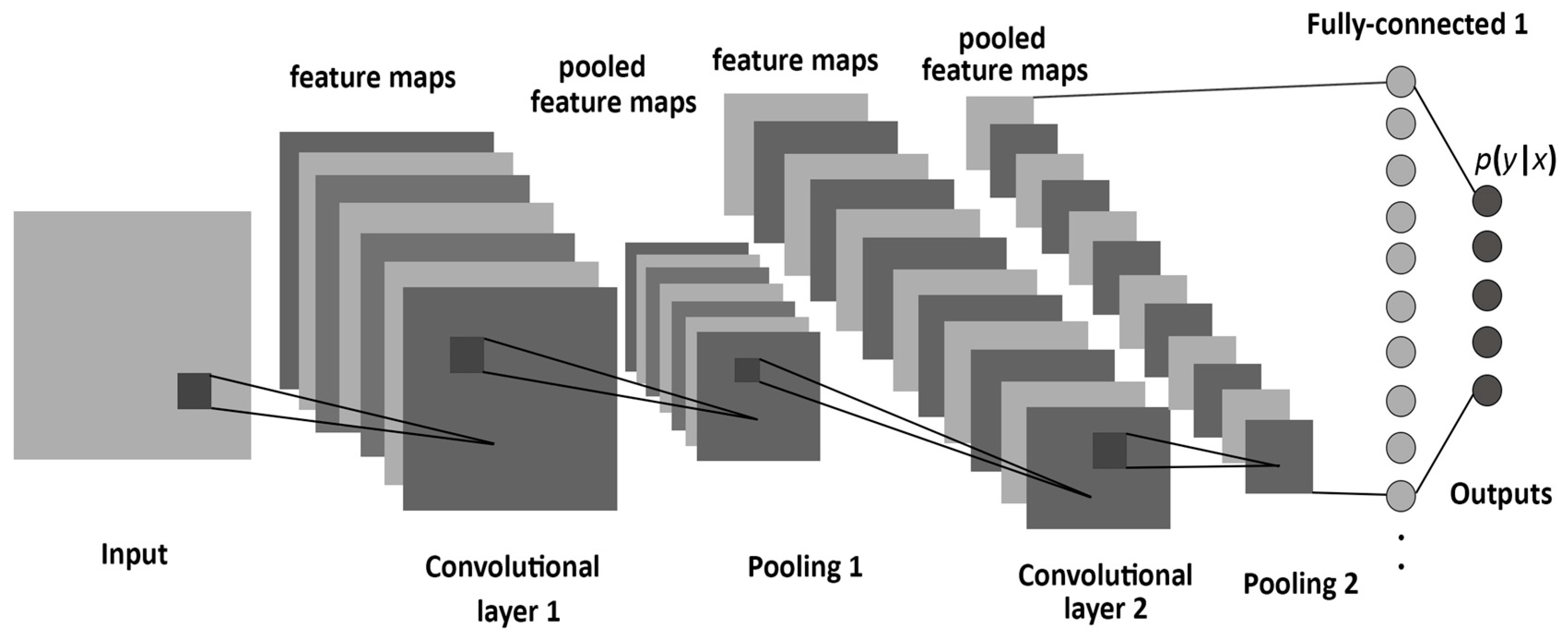
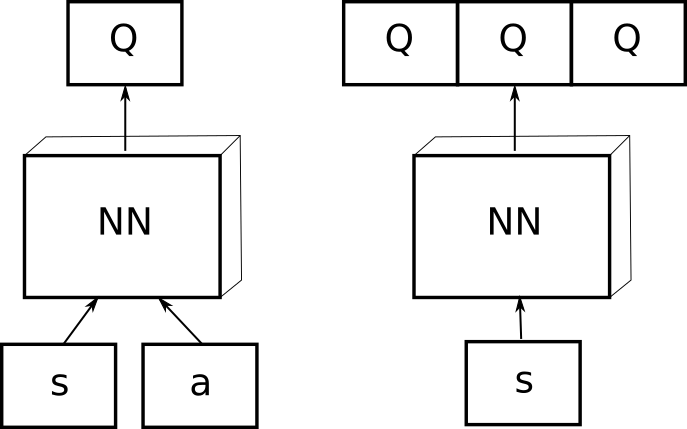
Dqn network structure. In the Seaquest game below, DQN learns how to read scores, shoot the enemy, and rescue divers from the raw images, all by itself. Let’s restart our journey back to the Deep Q-Network DQN. Where and represent the parameters of the state-value function and action advantage function, respectively and represents the rest parameters of the network.3.
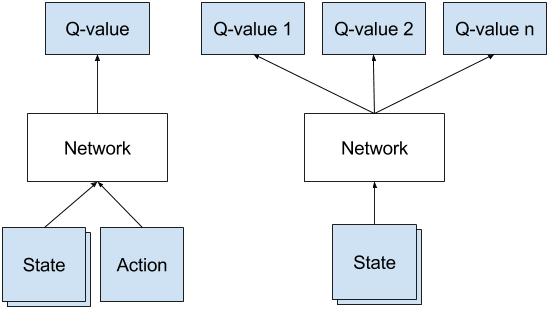
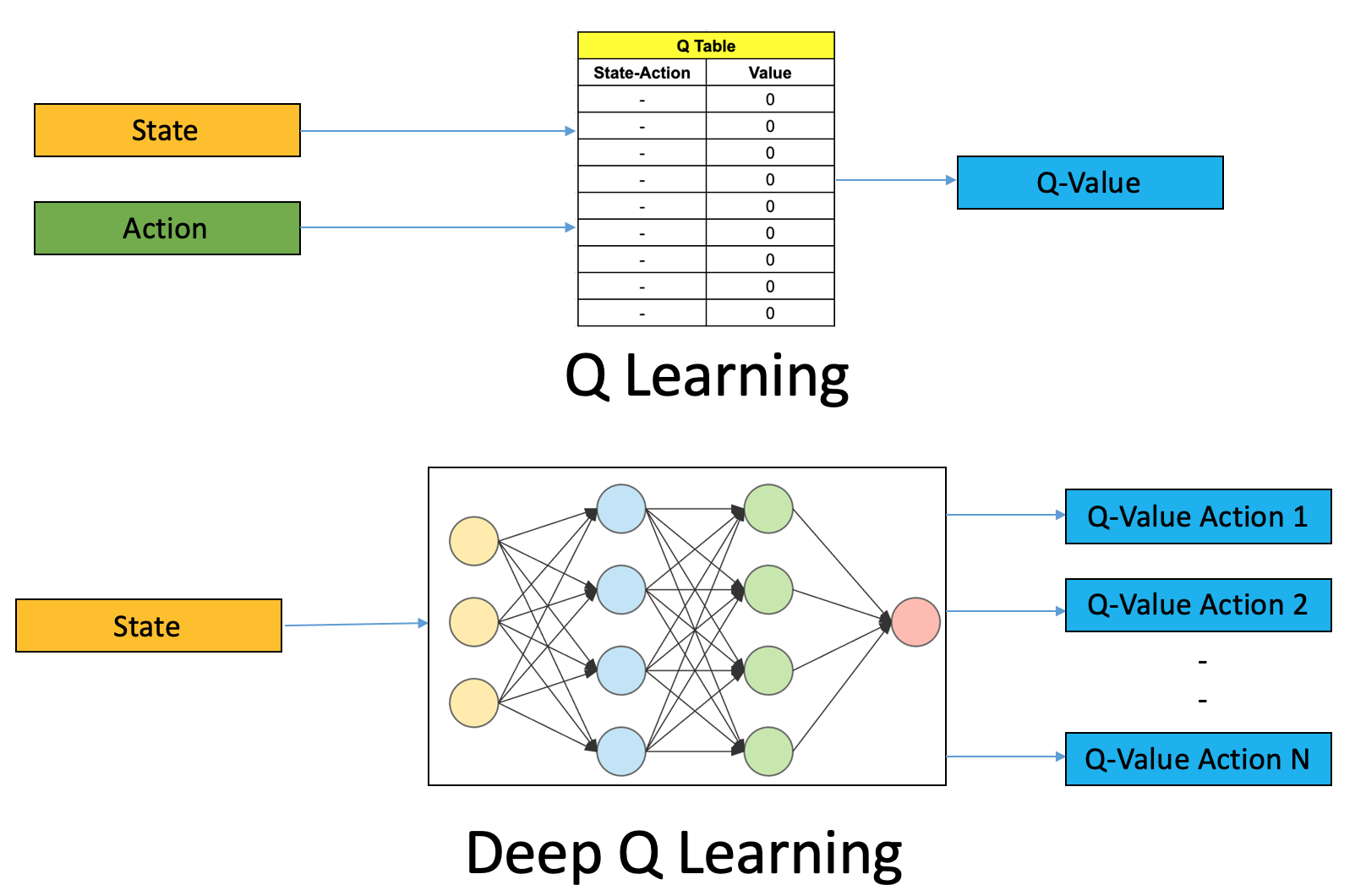
This disambiguation page lists articles associated with the title DQN. Deep Q-network (DQN) •An artificial agent for general Atari game playing –Learn to master 49 different Atari games directly from game screens –Beat the best performing learner from the same domain in 43 games –Excel human expert in 29 games. DQN is a deep neural network structure used for estimation of Q value of the Q-learning technique.
In addition, this deep neural network method also provides an end-to-end approach that an agent can learn a policy directly from his observations. This is a draft of Deep Q-Network, an introductory book to Deep Q-Networks for those familiar with reinforcement learning.DQN was the first successful attempt to incorporate deep learning into reinforcement learning algorithms. Value-based Deep RL 4.
In 13, Google Deepmind used a deep neural network, called DQN, to approximate the Q values in Q learning that overcomes the limitation of the state space of the traditional look-up table approach. The easiest way is to first install python only CNTK (instructions).CNTK provides several demo examples of deep RL.We will modify the DeepQNeuralNetwork.py to work with AirSim. Torch.Tensor - A multi-dimensional array with support for autograd operations like backward().Also holds the gradient w.r.t.
θ ) where r is the reward at current time step and s ′ and a ′ are states and actions of next time step. DQN Meetings will be run via Zoom webinars. This page was last edited on 4 June , at 07:38 (UTC).
13) and further improved in 15 (Mnih et al. Breakout-Deep-Q-Network 🏃 Reinforcement Learning tensorflow implementation of Deep Q Network (DQN), Dueling DQN and Double DQN performed on Atari Breakout Game Installation. Preprocess and feed the game screen (state s) to our DQN, which will return the Q-values of all possible actions in the state Select an action using the epsilon-greedy policy.
$ pip3 install opencv-python gym gymatari. Human-level control of Atari games. Before proceeding further, let’s recap all the classes you’ve seen so far.
Get the latest machine learning methods with code. Thanks to this procedure, we’ll have more stable learning because the target function stays fixed for a while. Policy-based Deep RL 6.
Target Q-network is initialized by the main Q-network (Q-network udder training) and updated by the main Q-network periodically. The network architecture for the classification follows exactly the structure of the hidden layers of DQN Mnih et al.15 with three convolutional layers (conv1, conv2, conv3) and one fully connected layer (fc1). An enhanced version of the original DQN was introduced nine months later that utilized its internal Neural Networks slightly differently in its learning process.
DQN (Deep Q-networks) 2. The researchers empirically evaluate the approach using deep Q-network (DQN) and asynchronous advantage actor-critic (A3C) algorithms on the Atari 2600 games of Pong, Freeway, and Beamrider. We separate the DQN into a super- vised deep learning structure and a Q-learning network.
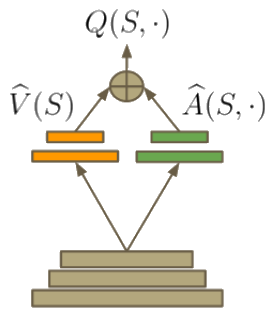
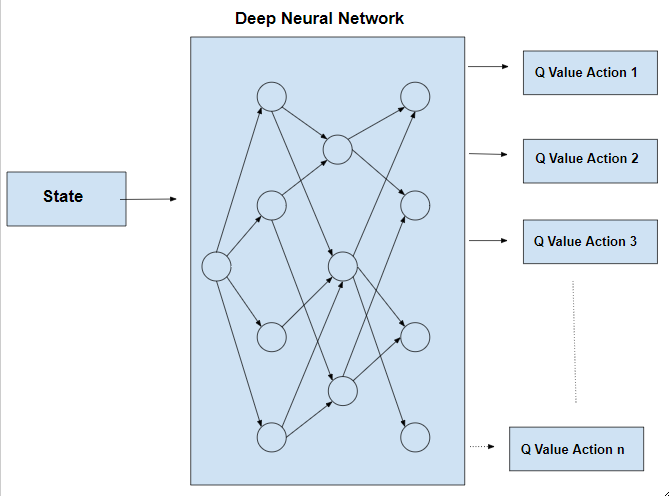
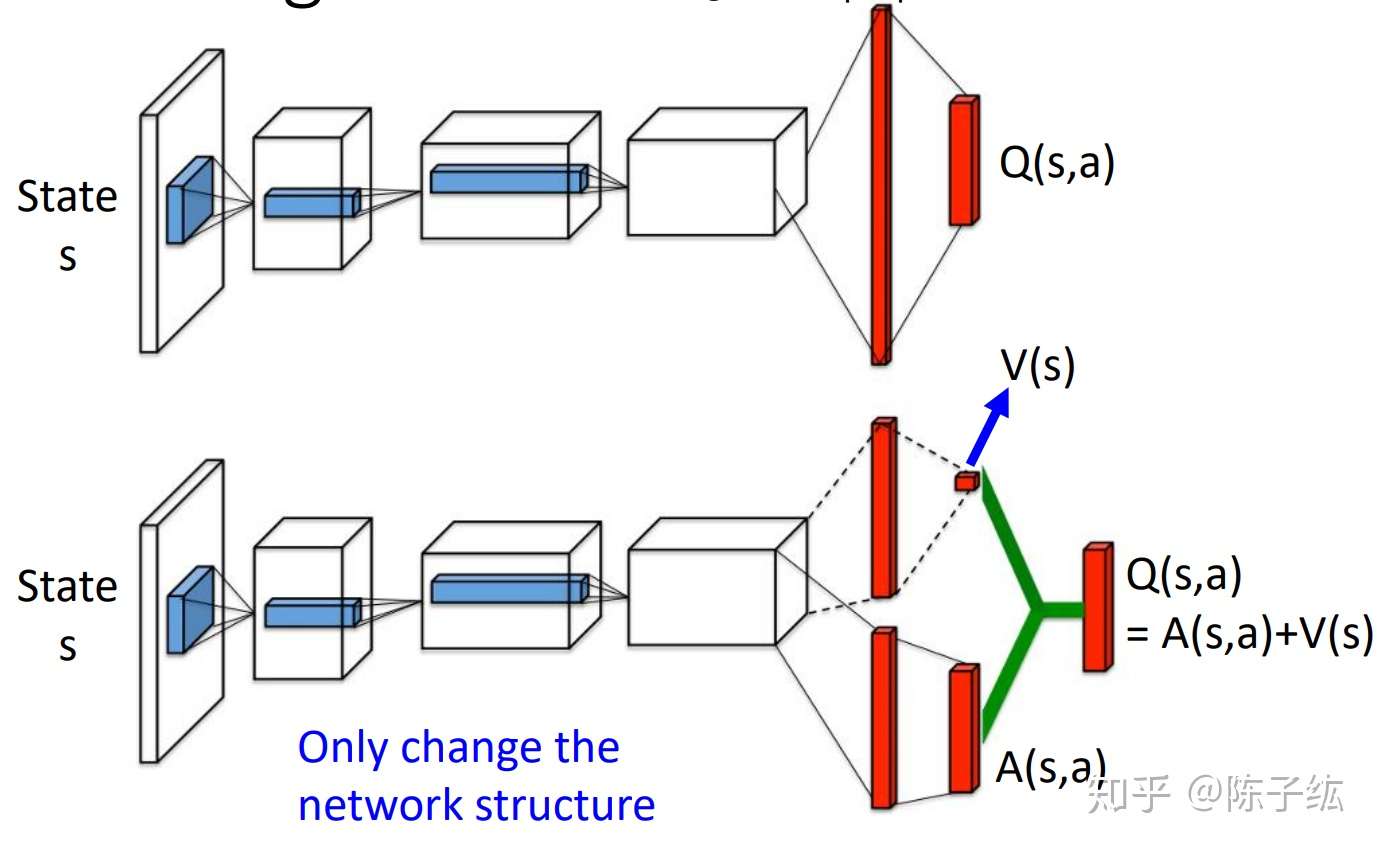
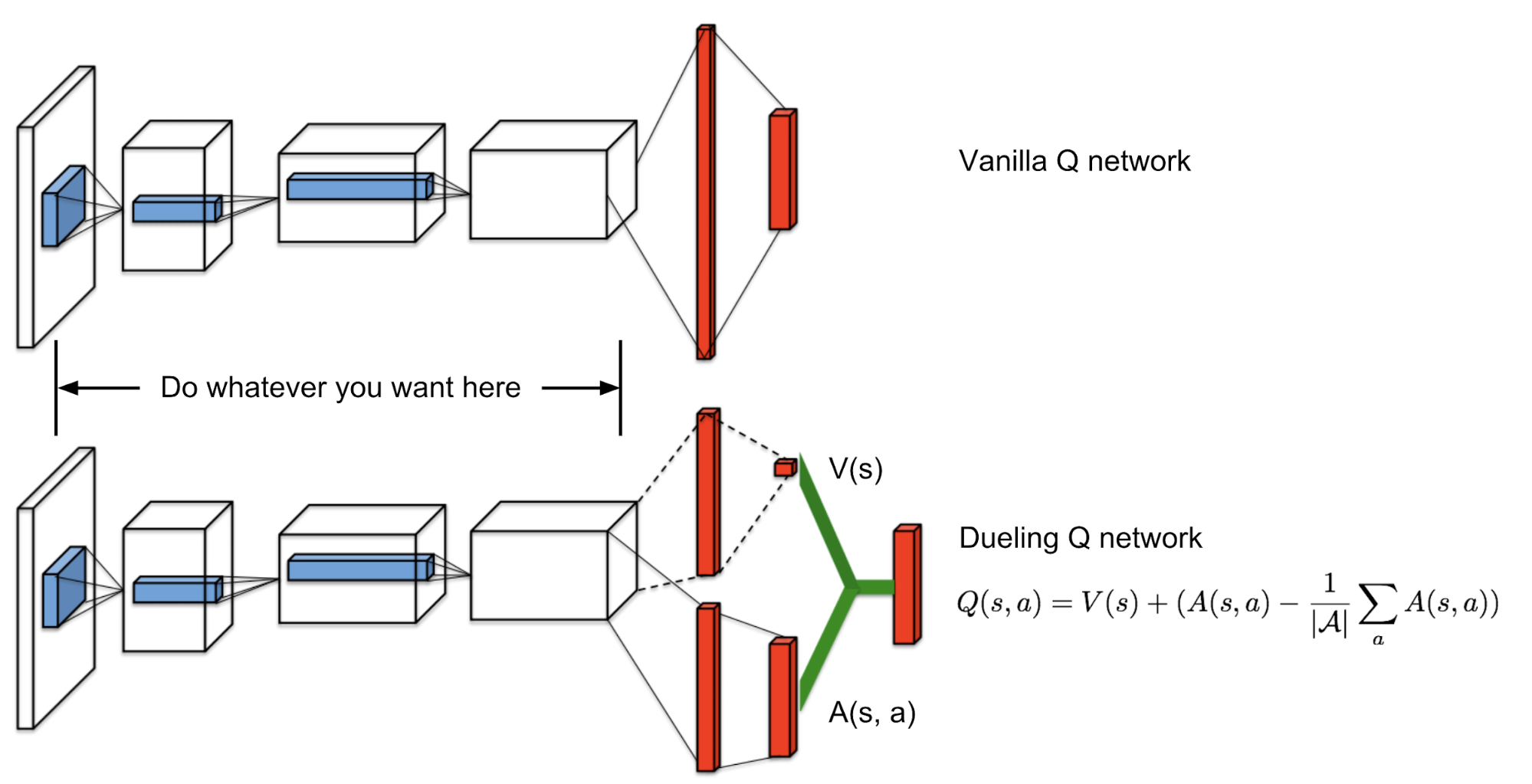
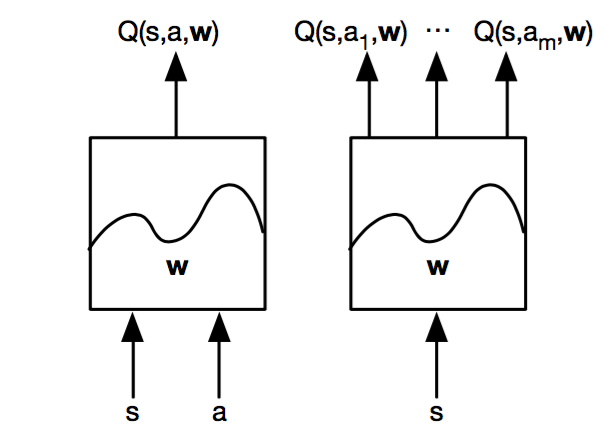
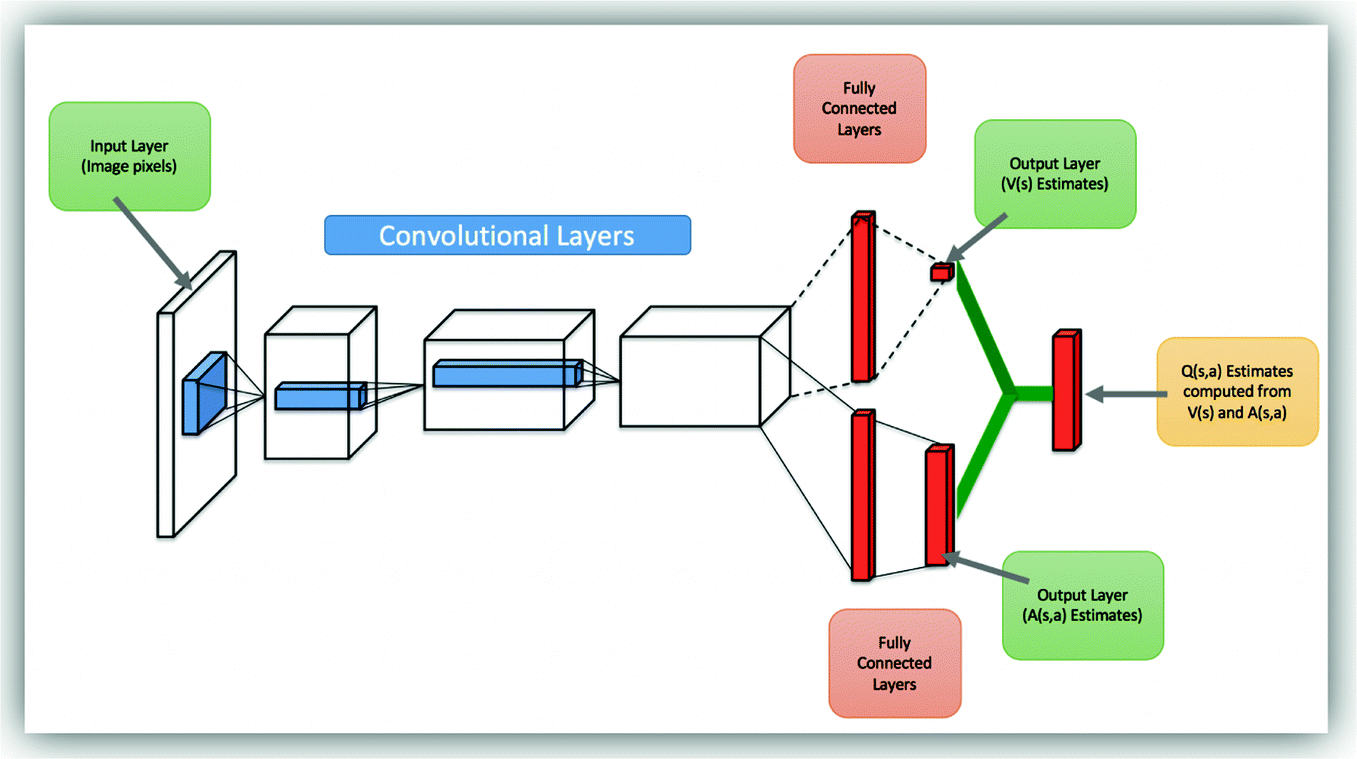
Hypothesis - batch size and neural network structure. The state-value function and the state-dependent action advantage function. In this work, we show that the compositional structure of the action modules has a significant impact on model performance.
The model part is used to define the network structure with neural network, which can be Q network or policy network, etc. This network structure can generalize learning across actions without imposing any change to the RL algorithm (ZiyuWang, 16). The results show that:.
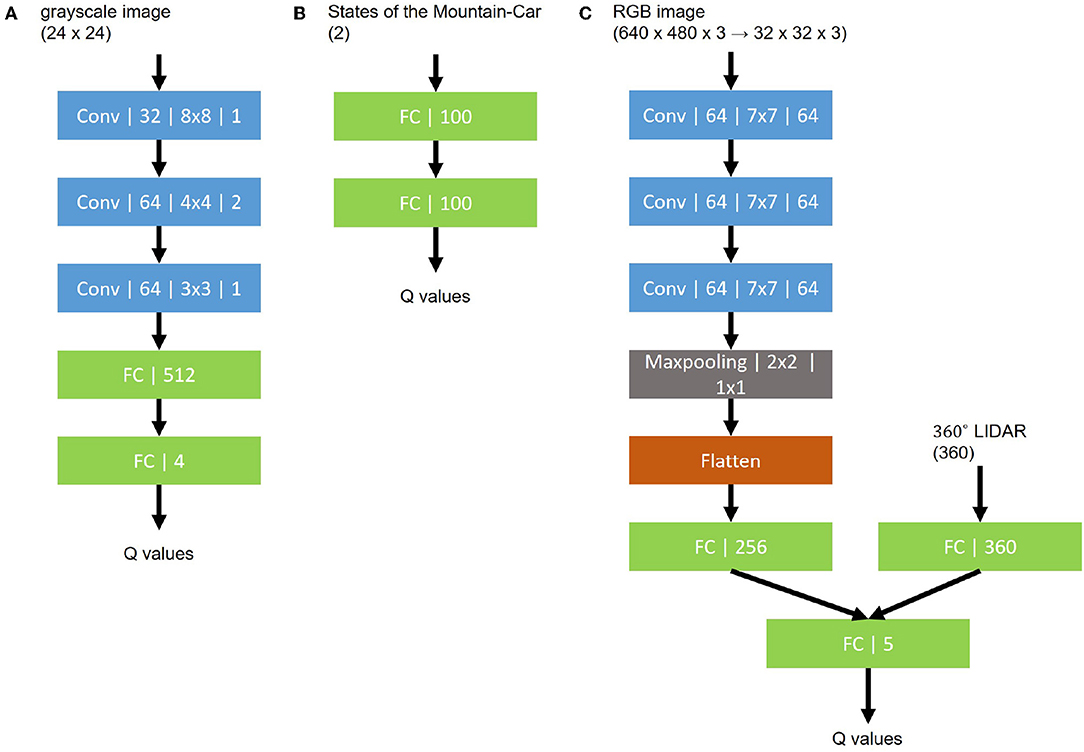
Due to the visual structure of the Atari Learning Environment games, the authors of the DQN paper chose to use a convolutional neural network (CNN). DQN approximate a set of values that are very interrelated (DDQN solves it) DQN tend to be overoptimistic. Reinforcement Learning Toolbox provides functions, Simulink blocks, templates, and examples for training deep neural network policies using DQN, C, DDPG, and other reinforcement learning algorithms.
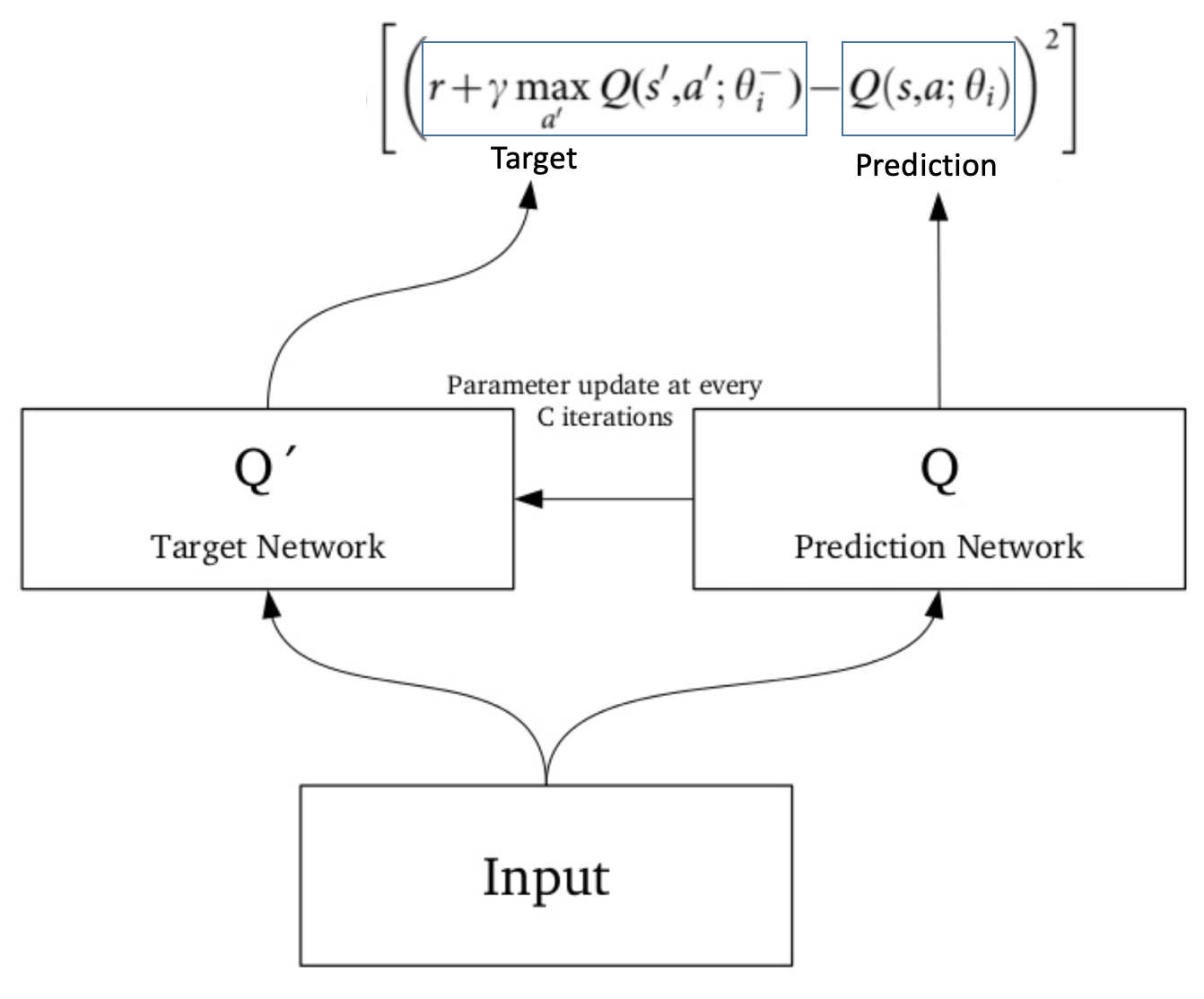
At time t, the target used by Double DQN is:. In DQN, the target Q-function is:. In recent years there have been many successes of using deep representations in reinforcement learning.
Atari screen), but does not generalize to other problems. Our Deep Q-Network (DQN) surpassed the overall performance of professional players in 49 different Atari games using only raw pixels and the score as inputs. Reinforcement Learning in AirSim#.
1) pre-training with. Naive DQN has 3 convolutional layers and 2 fully connected layers to estimate Q values directly from images. The Deep Q-Network (DQN) algorithm, as introduced by DeepMind in a NIPS 13 workshop paper, and later published in Nature 15 can be credited with revolutionizing reinforcement learning.
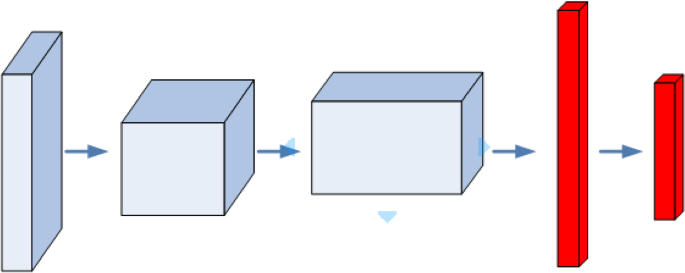
Browse our catalogue of tasks and access state-of-the-art solutions. Through exploration, the network takes actions and receives feedback, allowing it to learn about the parameter space and make intelligent choices. The DQN algorithm is a Q-learning algorithm, which uses a Deep Neural Network as a Q-value function approximator.
Source Link In the above fixed environment Q-Learning, if the state is replaced with the behavior through the Q table, the DQN replaces the state with the behavior through the Q network. The texture evo-lution network is a directed tree graph with crystallographic textures as vertices and process steps as edges. The target network has its weights kept frozen most of the time, but is updated with the.
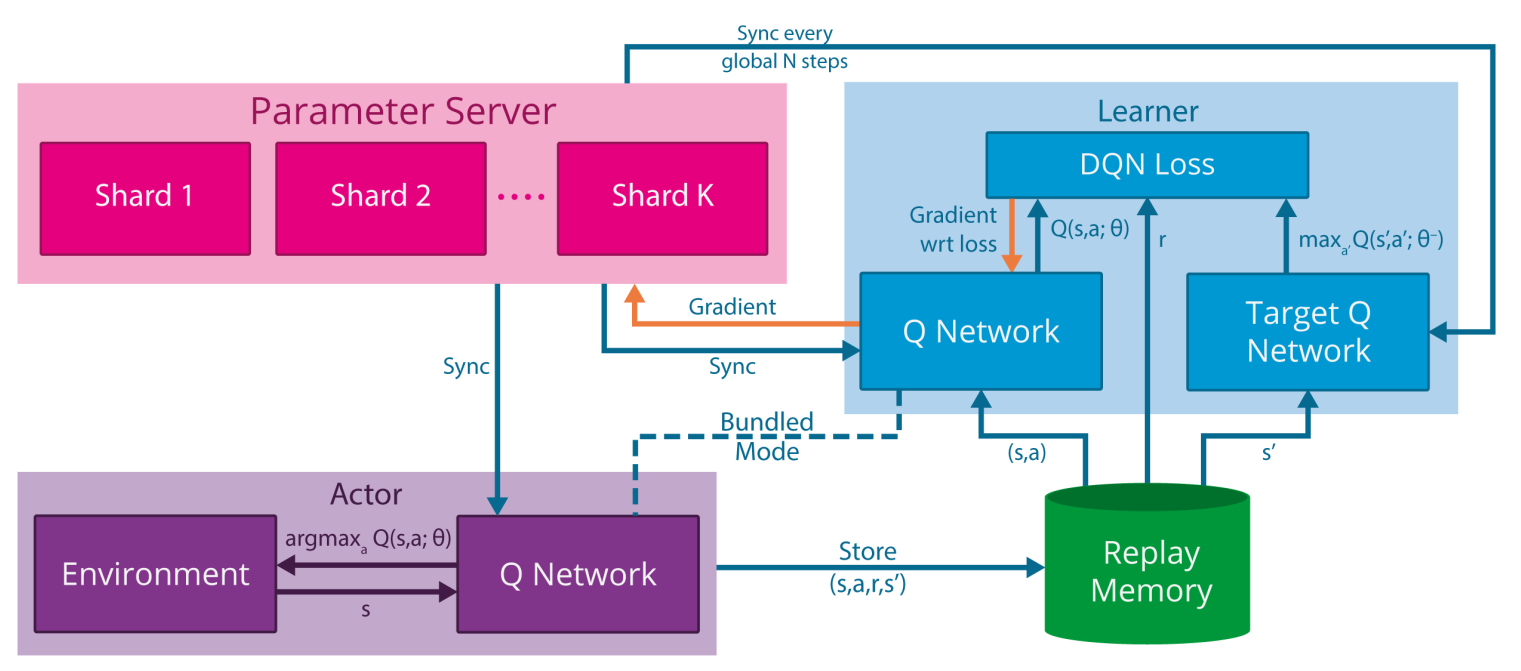
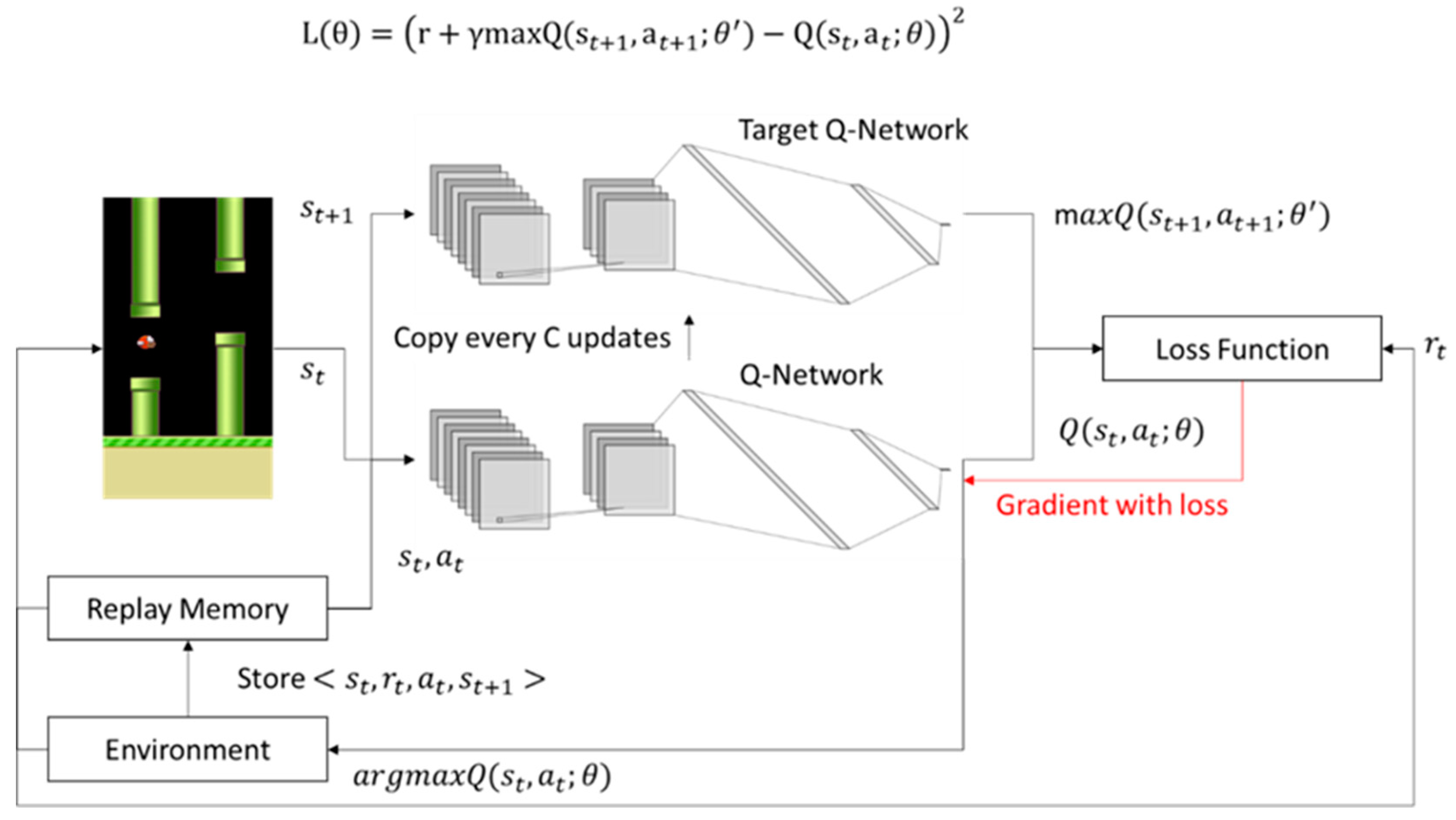
At every Tau step, we copy the parameters from our DQN network to update the target network. The detailsofthearchitectureareexplainedintheMethods.Theinputtotheneural network consists of an image produced by the preprocessing map w, followed by three convolutional layers (note:. After you register, you will receive an email with the webinar information that you can add to your calendar as a meeting invitation.
One for the. These embeddings capture the structure of the environment’s dynamics, enabling efficient policy learning. The system is based on the recent Deep Q-Network (DQN) framework where a convolution neural network structure was adopted in the Q-value estimation of the Q-learning method.
Text is available under the Creative. The network takes state as an input and produces the probability distribution of actions. One for the state value function and the other for state-dependent action advantage function.
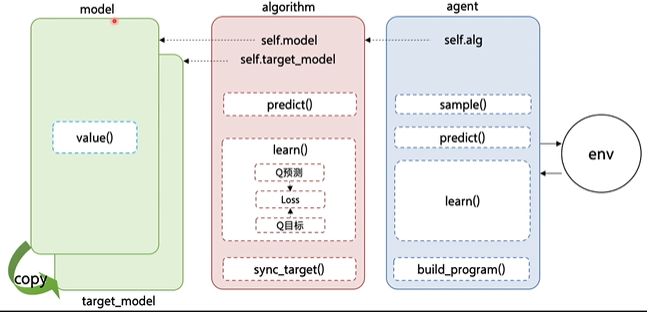
This approach works well on problems where the state space is naturally two dimensional (i.e. DQN implemented in PARL separates the nested parts:. I have listed the steps involved in a deep Q-network (DQN) below:.
One of the great challenges in AI is building flexible systems that can take on a wide range of tasks. Deep Q-Network, used in Deep Q-learning;. We below describe how we can implement DQN in AirSim using CNTK.
Instantly share code, notes, and snippets. The proposed simulation system is implemented in Rust programming language. However there are a couple of statistical problems:.
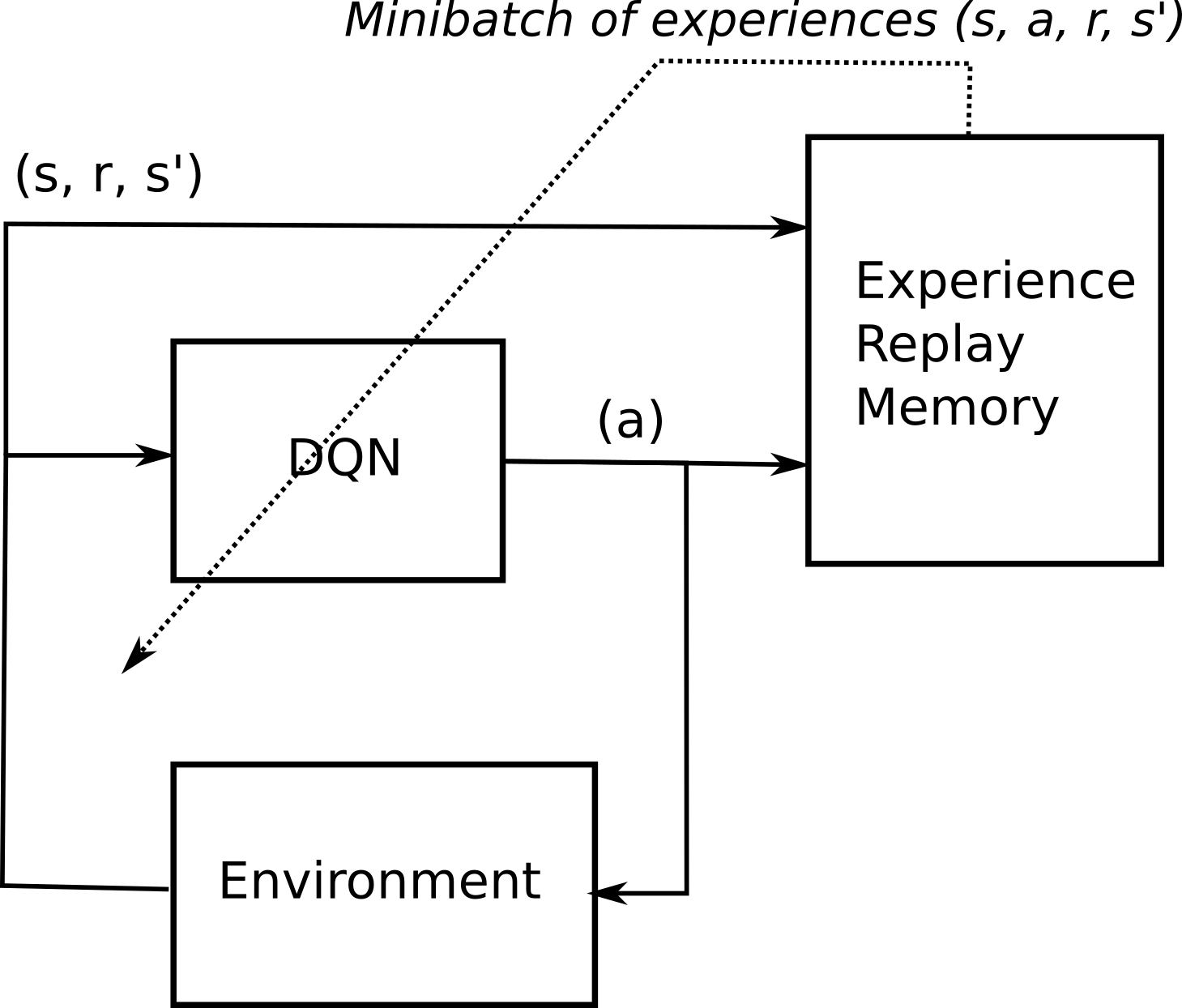
Once the graph is built, it is mapped to property space by a structure-property mapping. We estimate target Q-values by leveraging the Bellman equation, and gather experience through an epsilon-greedy policy. The weights of target Q-network stayed unchanged from DQN, and remains a periodic copy of the online network.
(15) y t = r + γ max a ′ Q ∗ ( s ′ , a ′ ;. Using a separate network with a fixed parameter (let’s call it w-) for estimating the TD target. Due to COVID-19, the -21 DQN meeting structure will be as follows:.
These organizations can either get into a partnership for a particular venture, or one organization can hire others to handle one or more of its functions (outsourcing), for example, marketing, production, sales and so on. The diagram is similar to DQN but this is a classification problem while DQN is a regression problem. A DQN, or Deep Q-Network, approximates a state-value function in a Q-Learning framework with a neural network.
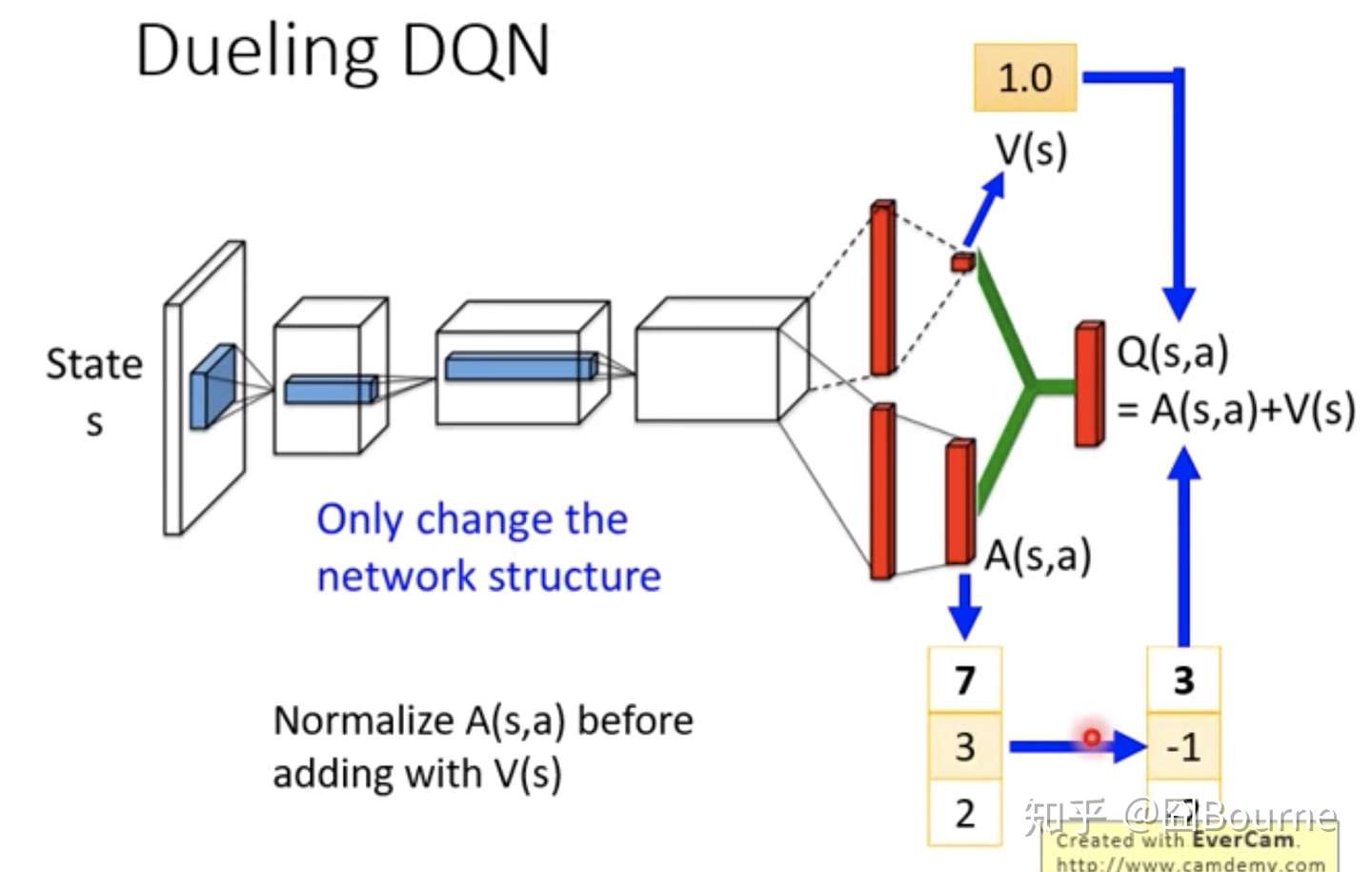
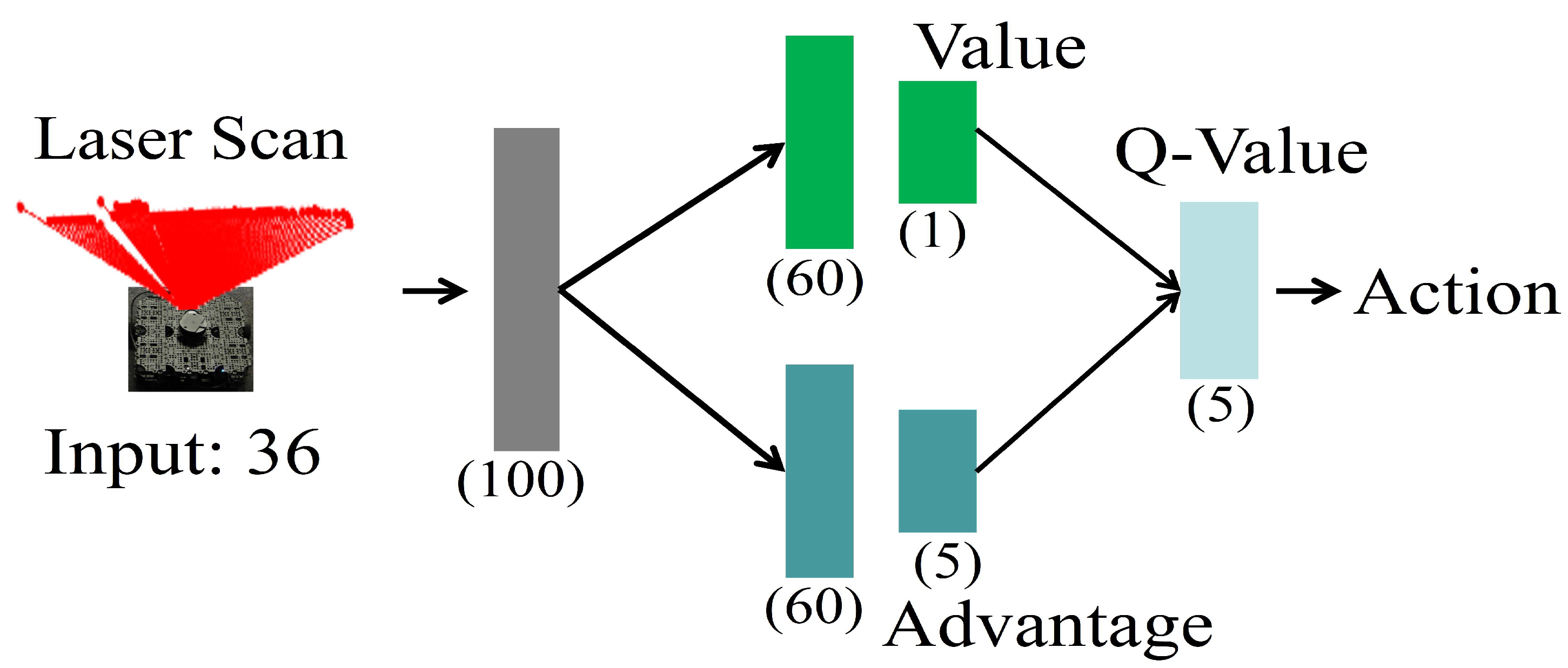
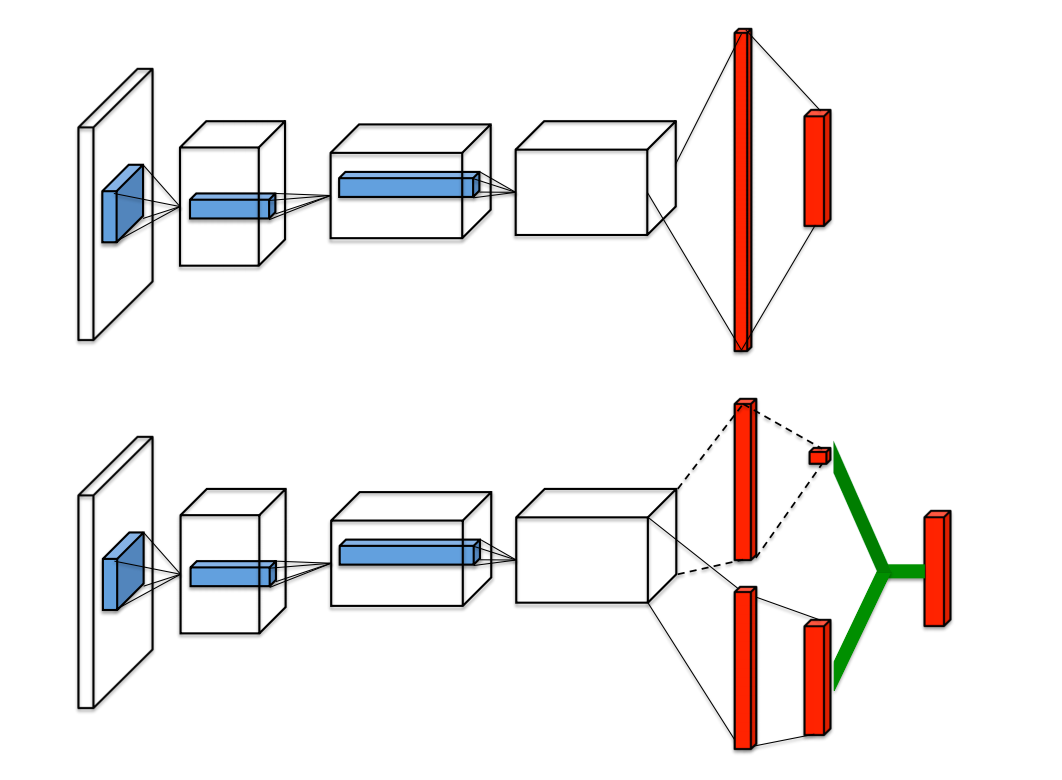
Our dueling network represents two separate estimators:. A network structure is the one in which more than one organization combine to produce a good or provide a service. This tutorial shows how to use PyTorch to train a Deep Q Learning (DQN) agent on the CartPole-v0 task from the OpenAI Gym.
DDoS Traffic Control using Transfer Learning DQN with Structure Information Article (PDF Available) in IEEE Access PP(99):1-1 · June 19 with 81 Reads How we measure 'reads'. (3) Y t = R t + 1 + γ Q (S t + 1, a r g m a x a Q (S t + 1, a;. Dueling network splits the Q value estimation into two streams:.
On the other hand, Linear model has only 1 fully connected layer with some learning techniques talked in the next section. Comparison between naive DQN and linear model (with DQN techniques) from Nature. For more stability, we sample past experiences randomly (Experience Replay).
However, these approaches leverage a convolutional network structure for the DQN, and require the state space to be represented as a two dimensional grid. In original paper authors use convolutional network, which takes your image pixels and then fit it into a set of convolutional layers. Online RL incrementally update the parameters while observing a stream of experience.
Type the following command to install OpenAI Gym Atari environment. Before every DQN meeting, you will receive an email from your DQN Point-of-Contact (PoC) to register for the webinar. The agent implemented in this tutorial follows the structure of the original DQN introduced in this paper, but is closer to what is known as a Double DQN.
Convenient way of encapsulating parameters, with helpers for moving them to GPU, exporting, loading, etc. This leads to problems:. Approach, in 6, a so-called texture evolution network is built based on a priori sampled processing paths.
Snaking blue line symbolizes sliding of each filter across input image) and two fully connected layers with a single output for each valid action. In this post, therefore, I would like to give a guide to a subset of the DQN algorithm. Our method is based on the uncertainty estimation techniques introduced in the paper.
In Double DQN, the target is:. Code analysis of PARL DQN. Env = make_env(DEFAULT_ENV_NAME) net = DQN(env.observation_space.shape, env.action_space.n).to(device) target_net = DQN(env.observation_space.shape, env.action_space.n).to(device) buffer = ExperienceReplay(replay_size) agent = Agent(env, buffer) epsilon = eps_start optimizer = optim.Adam(net.parameters(), lr=learning_rate) total_rewards = frame_idx = 0 best_mean_reward = None.
Prioritized Experience Replay Background. As shown in equation (), the dueling DQN divides the output of the neural network into two parts:. Use our DQN network to.
θ t), θ t −) where γ is the discount factor set to the experience value 0.8 and the target network with parameters θ t −, is the same as the online network except that its parameters are copied every τ steps from the online network and kept fixed for all other steps. In the Atari Games case, they take in several frames of the game as an input and output state values for each action as an output. The deep Q-network (DQN), a reinforcement learning algorithm is a powerful tool that can be used to optimize solutions for a problem 29, 31,32,33,34,35 by acting as an intelligent search.
Still, many of these applications use conventional architectures, such as convolutional networks, LSTMs, or auto-encoders. The target for each observed environment state is defined as:. Not sure how "intuitive" it is for you (depends on your understanding of deep neural networks and reinforcement learning) but this is how the Google DeepMind team explains it in a recent blog post (follow link at the end):.
In DQN the online network is changed at each step by minimizing the difference between the Bellman target and the current network approximation of Q (s,a). The network’s output layer also has a single output for each valid action but it uses the cross-entropy loss instead of the TD loss. It is usually used in conjunction with Experience Replay, for storing the episode steps in memory for off-policy learning, where samples are drawn from.
The schematic network structure of DQN. We propose a novel approach to infer the network structure for DQN models operating with high-dimensional continuous actions. If an internal link led you here, you may wish to change the link to point directly to the intended article.
Here is the framework of the PARL:. Model-based Deep RL 5. The CNN has the following layers:.
In this paper, we present a new neural network architecture for model-free reinforcement learning. Thus, DQNs have been a crucial part of deep reinforcement learning, and they are worth a full book for discussion. No code available yet.

Graphical Representation Of The Dqn The Network Takes In Input Four 84 Download Scientific Diagram
Introduction To Dueling Double Deep Q Network D3qn By Rokas Balsys Analytics Vidhya Medium
Web Stanford Edu Class Psych9 Readings Mnihetalhassibis15naturecontroldeeprl Pdf
Udacity Banana Navigation Project Report 知乎

The Structure Of Evaluation Network And Target Network Of Agent I Download Scientific Diagram
Deep Reinforcement Learning
Deep Q Learning An Introduction To Deep Reinforcement Learning
Path Planning For Active Slam Based On Deep Reinforcement Learning Under Unknown Environments Springerlink

David Silver Google Deepmind Deep Reinforcement Learning Synced
Arxiv Org Pdf 1602
Www Cs Toronto Edu Vmnih Docs Dqn Pdf
Http Ifaamas Org Proceedings mas18 Pdfs P13 Pdf

Network Construction And Training Java Deep Learning Projects Book

Q Learning Wikipedia

The Dqn Model Based On The Dual Network For Direct Marketing Semantic Scholar
Papers Nips Cc Paper 6501 Deep Exploration Via Bootstrapped Dqn Pdf
Deep Q Learning Geeksforgeeks

Dueling Network Architectures For Deep Reinforcement Learning
Rl By Hung Yi Lee L2 Q Learning 知乎
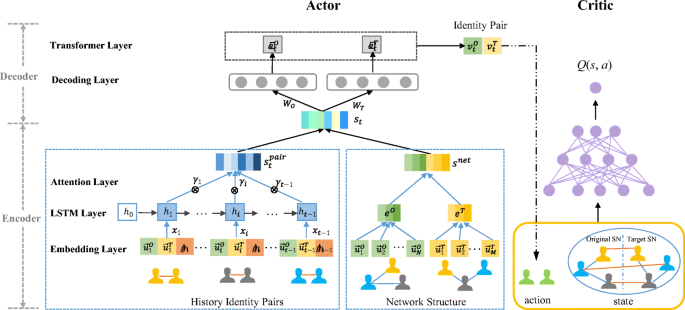
Rlink Deep Reinforcement Learning For User Identity Linkage Springerlink
Unpaywall Org 10 1109 2fitsc 17

Vanilla Deep Q Networks Deep Q Learning Explained By Chris Yoon Towards Data Science
Openreview Net Pdf Id Byxhb3r5tx
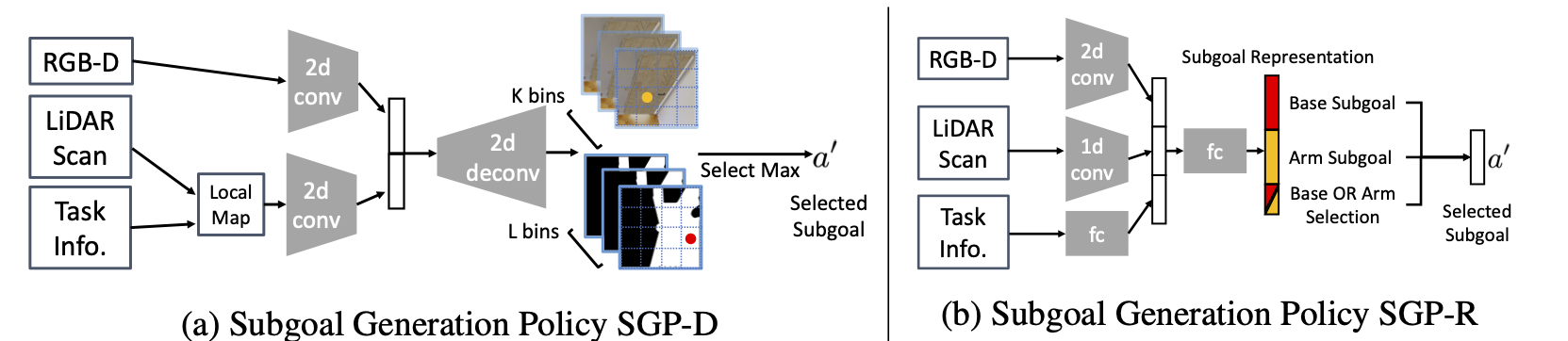
Relmogen Leveraging Motion Generation In Reinforcement Learning For Mobile Manipulation
Sensors Free Full Text Towards Goal Directed Navigation Through Combining Learning Based Global And Local Planners Html
Deep Reinforcement Learning Doesn T Work Yet

Evaluate Deep Q Learning For Sequential Targeted Marketing With 10 Fo
Implementing Deep Reinforcement Learning Models With Tensorflow Openai Gym
Beyond Dqn A3c A Survey In Advanced Reinforcement Learning By Joyce Xu Towards Data Science
Cartpole With A Deep Q Network
Demystifying Deep Reinforcement Learning Computational Neuroscience Lab
Masters Thesis Prioritized Experience Replay Based On The Wasserstein Metric In Deep Reinforcement Learning
Deep Reinforcement Learning

Python Tensorflow Deep Q Network Dqn 迷宮示例程式碼整理 It閱讀

Reinforcement Learning Dqn Tutorial Pytorch Tutorials 1 6 0 Documentation

Deep Reinforcement Learning For Multi Agent Systems A Review Of Challenges Solutions And Applications Deepai
Ddqn Hyperparameter Tuning Using Open Ai Gym Cartpole The Intersection Of Energy And Machine Learning
Electronics Free Full Text Using A Reinforcement Q Learning Based Deep Neural Network For Playing Video Games Html
Simple Reinforcement Learning With Tensorflow Part 4 Deep Q Networks And Beyond By Arthur Juliani Medium

The Dqn Architecture Applicable To The Sdn Based Wlan Download Scientific Diagram
Recap Deep Q Learning Recap Research Nodedown

Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed
Reinforcement Learning From Zero Practice Based On Neural Network Method For Rl Parl

Figure 2 From 3dcnn Dqn Rnn A Deep Reinforcement Learning Framework For Semantic Parsing Of Large Scale 3d Point Clouds Semantic Scholar

Dqn Architecture For End To End Learning Of Atari 2600 Game Plays Download Scientific Diagram
Torch Dueling Deep Q Networks

Easy Model Building With Keras To Implement Dqn

Deep Reinforcement Learning With Smooth Policy Update Application To Robotic Cloth Manipulation Sciencedirect

Double Dqn Reinforcement Learning Coach 0 12 0 Documentation

The Network Structure Of Dqn Download Scientific Diagram
Human Level Control Through Deep Reinforcement Learning Nature
Deep Reinforcement Learning
Frontiers Constrained Deep Q Learning Gradually Approaching Ordinary Q Learning Frontiers In Neurorobotics
Q Tbn 3aand9gct9nay65nz9jnygtqujzpt3wzpfmhjxi9hohz7mq0n28trmcynw Usqp Cau
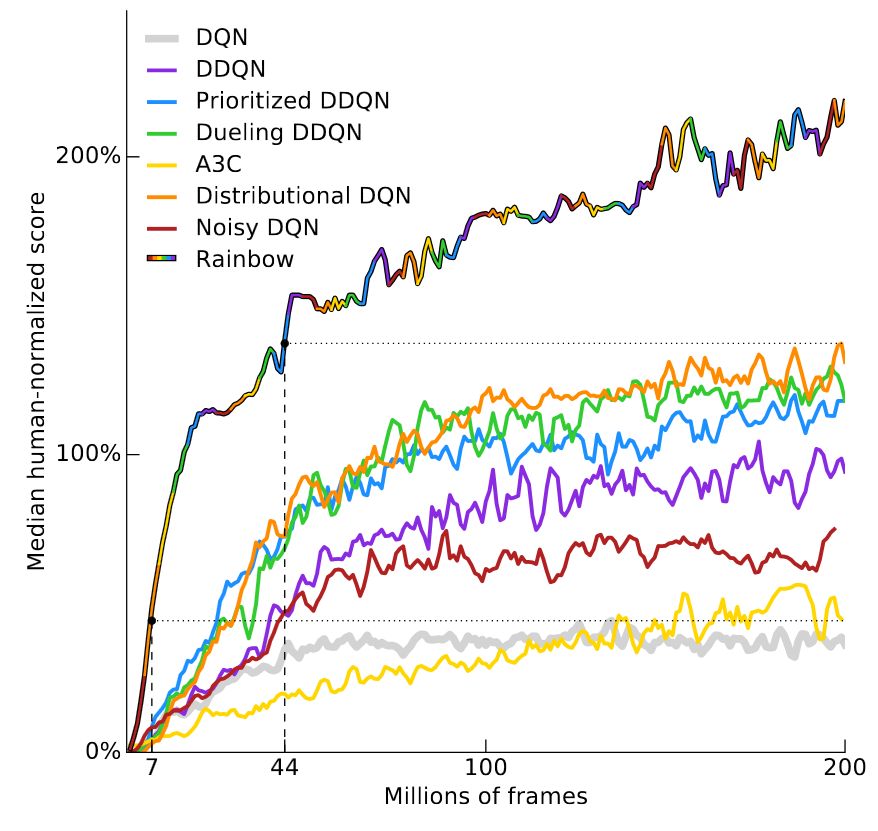
Week 5 Deep Q Networks And Rainbow Algorithm Holly Grimm

Dueling Q Networks In Tensorflow 2 Adventures In Machine Learning

3dcnn Dqn Rnn A Deep Reinforcement Learning Framework For Semantic Parsing Of Large Scale 3d Point Clouds
Arxiv Org Pdf 1707
2

A Dynamic Adjusting Reward Function Method For Deep Reinforcement Learning With Adjustable Parameters
Frontiers Constrained Deep Q Learning Gradually Approaching Ordinary Q Learning Frontiers In Neurorobotics

David Silver Google Deepmind Deep Reinforcement Learning Synced

Summary Of Reinforcement Learning 6 Astroblog

Dynamic Frame Skip Deep Q Network Arxiv Vanity

Double Deep Q Network Dqn Based Reinforcement Learning Darling For Download Scientific Diagram
Deep Q Learning An Introduction To Deep Reinforcement Learning

The Idea Behind Actor Critics And How c And A3c Improve Them Ai Summer
3

Dueling Dqn Reinforcement Learning Coach 0 12 0 Documentation

Dqn Method Based On Neural Network Programmer Sought

Decentralized Network Level Adaptive Signal Control By Multi Agent Deep Reinforcement Learning Sciencedirect

Research On Dynamic Path Planning Of Wheeled Robot Based On Deep Reinforcement Learning On The Slope Ground
Openreview Net Pdf Id Rj8je4clg
Arxiv Org Pdf 1602
Deep Q Learning An Introduction To Deep Reinforcement Learning

Part 2 Kinds Of Rl Algorithms Spinning Up Documentation
Deep Q Network Dqn Double Dqn And Dueling Dqn Springerlink

Deep Q Network Dqn Ii Laptrinhx
Ddqn Hyperparameter Tuning Using Open Ai Gym Cartpole The Intersection Of Energy And Machine Learning

Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed
Ieeexplore Ieee Org Iel7 Pdf
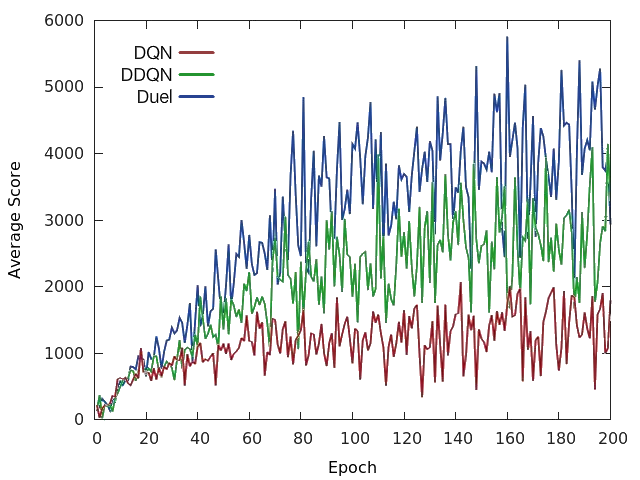
Torch Dueling Deep Q Networks
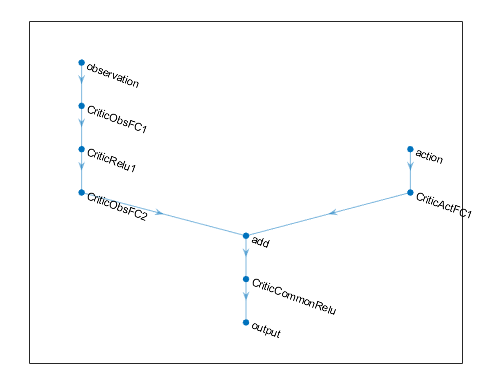
Create Policy And Value Function Representations Matlab Simulink Mathworks France

Simple Reinforcement Learning With Tensorflow Part 4 Deep Q Networks And Beyond By Arthur Juliani Medium
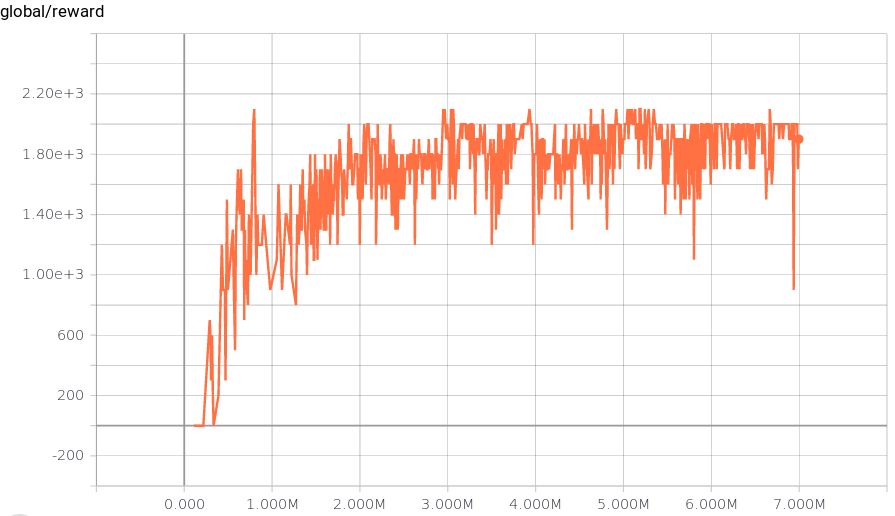
Week 5 Deep Q Networks And Rainbow Algorithm Holly Grimm

Drl Lecture 4 Q Learning Advanced Tips Youtube
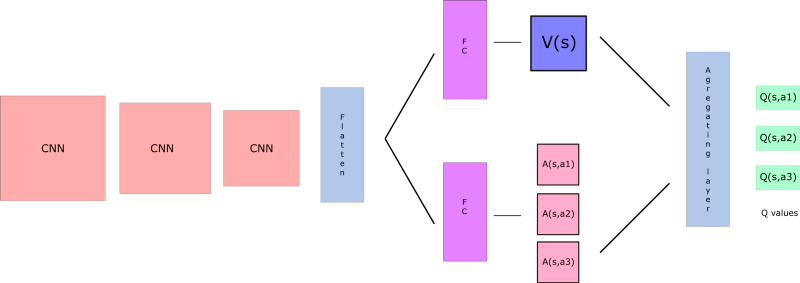
Dueling Deep Q Networks Dueling Network Architectures For Deep By Chris Yoon Towards Data Science
Application Of Deep Neural Network And Deep Reinforcement Learning In Wireless Communication

A Survey Of Deep Reinforcement Learning In Video Games Deepai
Papers Nips Cc Paper 6501 Deep Exploration Via Bootstrapped Dqn Pdf
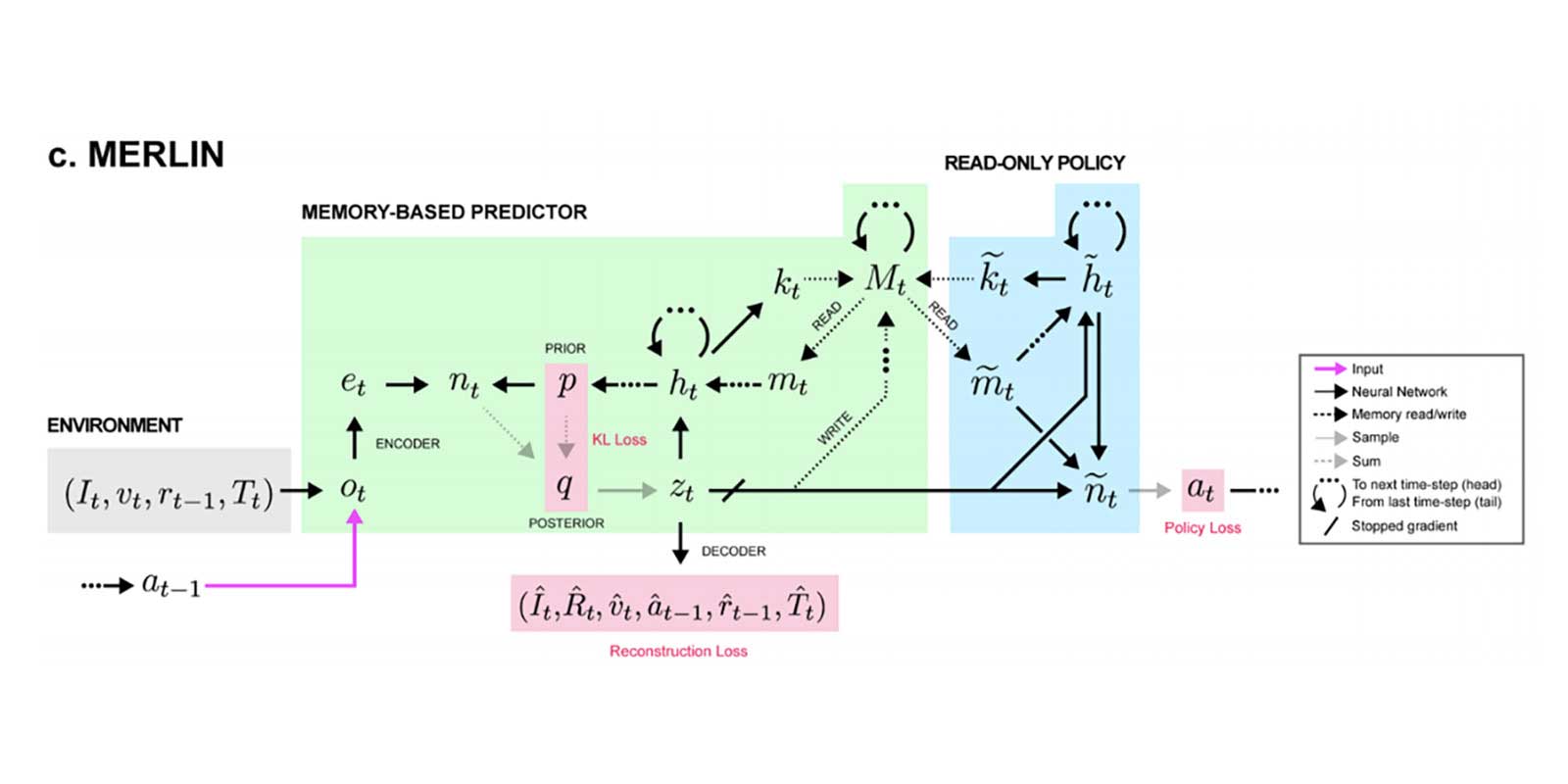
Beyond Dqn A3c A Survey In Advanced Reinforcement Learning

Multi Pass Q Networks For Deep Reinforcement Learning With Parameterised Action Spaces
Q Tbn 3aand9gctyjenhhqro05br3k9fqk0yiptj48mmfyjrvkp4z4jj5aq9qkyb Usqp Cau
Q Tbn 3aand9gctkrgcpuo8hkymkivuybxzb85gprdgmuq0sizhys4m62uzdt Tm Usqp Cau
Overall Network Structure Of Dqn Download Scientific Diagram

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium
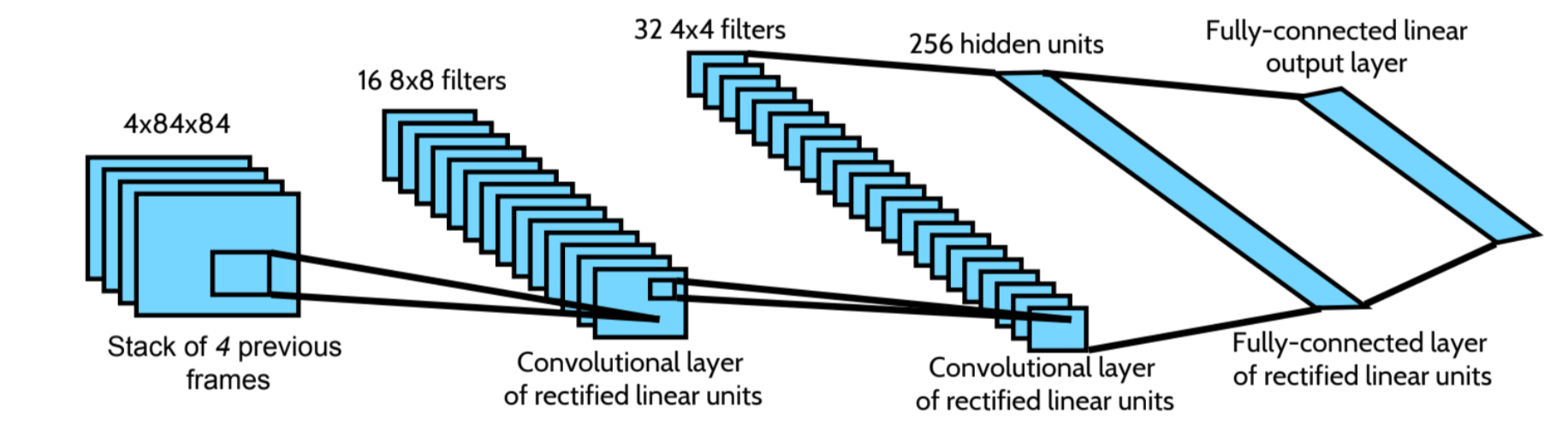
Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium
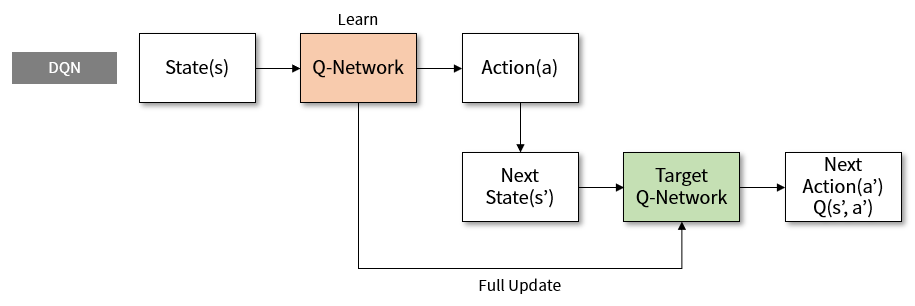
Learn Reinforcement Learning 3 Dqn Improvement And Deep Sarsa Greentec S Blog



