Dqn Algorithm Tutorial

Reinforcement Learning A Deep Dive Toptal

Reinforcement Learning Python Dqn Application For Resource Allocation Machine Learning Applications
Week 5 Deep Q Networks And Rainbow Algorithm Holly Grimm

Deep Deterministic Policy Gradient Spinning Up Documentation
Reinforcement Learning Tutorial Javatpoint
Web Stanford Edu Class Cs234 Slides Lnotes6 Pdf
Deep reinforcement learning, python, q-learning, Reinforcement Learning.
Dqn algorithm tutorial. Use Bellman equation as an iterative update. Proposed algorithm, named Minimax-DQN, can be viewed as a combination of the Minimax-Q learning algorithm for tabular zero-sum Markov games (Littman, 1994) and deep neural networks for function approximation. The general formula of the Bellman equation used by the agent implemented here is:.
Also, traditional learning algorithms are not able to do feature extraction :. I've run it with Tensorflow 1.0 on Python 3.5 under Windows 7. An example of an environment is the laws of physics.
Furthermore, in RL the data distribu-tion changes as the algorithm learns new behaviours, which can be problematic for deep learning. In this paper, we answer all these questions affirmatively. Keras-rl implements some state-of-the art deep reinforcement learning algorithms in Python and seamlessly integrates with the deep learning library Keras.
DQN (used in this tutorial). You could say that an algorithm is a method to more quickly aggregate the lessons of time. I encourage you to try the DQN algorithm on at least 1 environment other than CartPole to practice and understand how you can tune the model to get the best results.
The environment requires the agent to go to the end of a corridor before coming back in order to receive a larger reward. We've built our Q-Table which contains all of our possible discrete states. The DQN (Deep Q-Network) algorithm was developed by DeepMind in 15.
This is a deep dive into deep reinforcement learning. 2.3 Deep Q Network (DQN) Although Q-learning is a very powerful algorithm, its main weakness is lack of generality. This one summarizes all of the RL tutorials, RL courses, and some of the important RL papers including sample code of RL algorithms.
An algorithm is an example of an agent. Artificial intelligence specialists need to figure out a good data representation which is then sent to the learning algorithm. Implementation Dueling DQN (aka DDQN) Theory.
Of course you can extend keras-rl according to your own needs. 16 on the Long Corridor environment also explained in Kulkarni et al. The original DQN architecture contains a several more tweaks for better training, but we are going to stick to a simpler version for now.
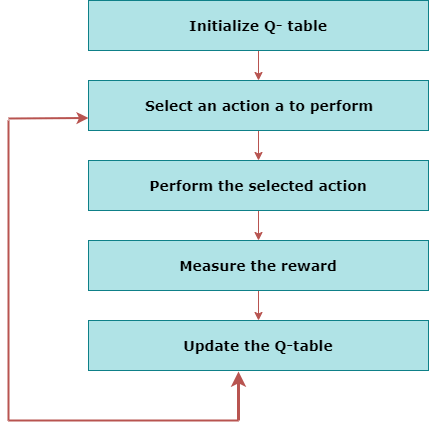
Use Reinforcement Learning Toolbox™ and the DQN algorithm to perform image-based inversion of a simple pendulum. There are many RL tutorials, courses, papers in the internet. An algorithm which produces a Q-table that an agent uses to find the best action to take given a state.
The following is the algorithm to fit Q with the sampled rewards. An implementation of Reinforcement Learning. The theory of reinforcement learning provides a normative account deeply rooted in psychological and neuroscientific perspectives on animal behaviour, of how agents may optimize their control of an environment.
Transitions of the form ) collected from. Q-learning is a popular model-free reinforcement learning algorithm based on the Bellman equation. There was one key thing that was excluded in the initialization of the DQN above:.
This updated algorithm can still legitimately be called a Double Q algorithm, but the author called it Double DQN (or DDQN) to disambiguate. You can find an official leaderboard with various algorithms and visualizations at the Gym website. I strongly recommend that you skim through the paper before reading this tutorial, and then read it more deeply when you are done.
Therefore, SARSA is an on-policy algorithm. After the end of this tutorial, you will be able to…. Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 14 - May 23, 17 Solving for the optimal policy:.
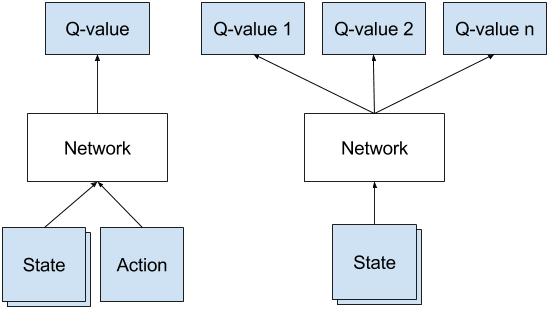
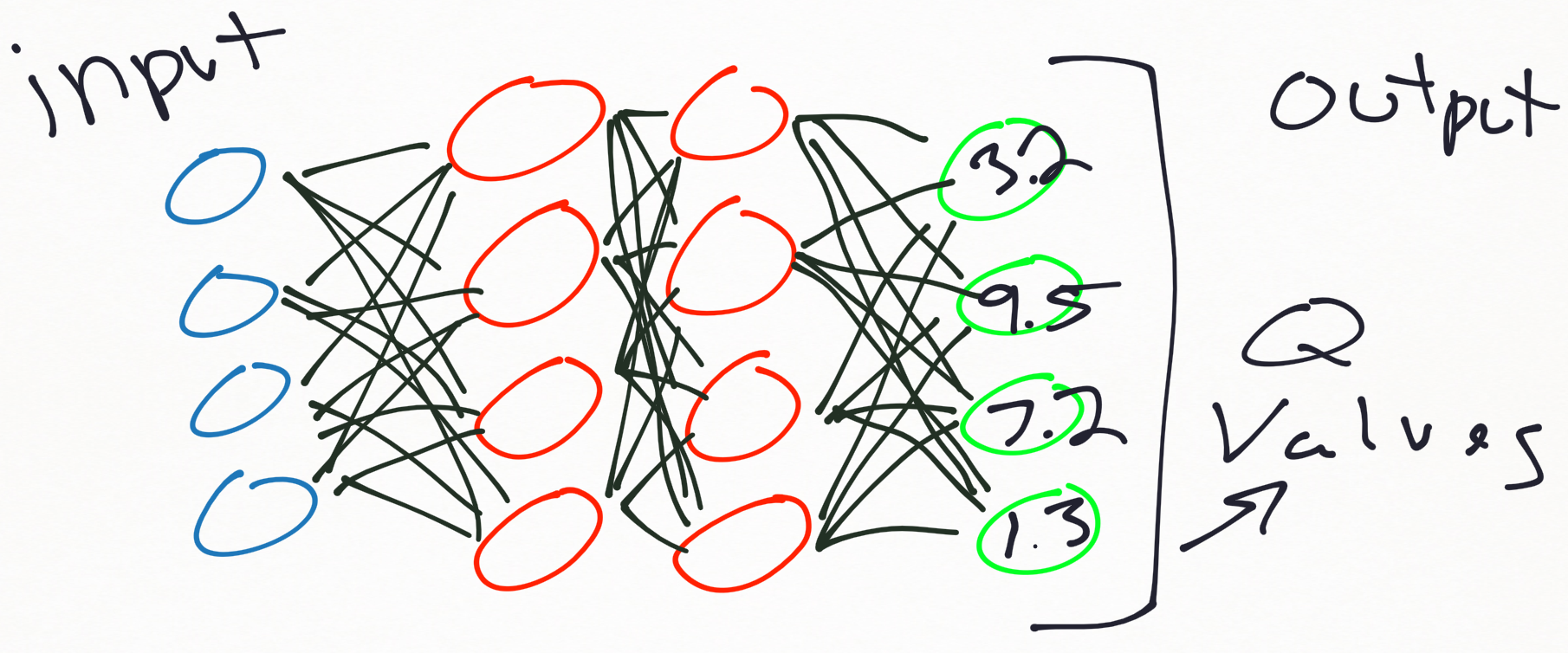
The DQN neural network model is a regression model, which typically will output values for each of our possible actions. Remember that Q-values correspond to how good it is to be at that state and taking an action at that state Q(s,a). This is a Deep Reinforcement Learning solution to the CartPole-v0 environment in OpenAI's Gym.This code uses Tensorflow to model a value function for a Reinforcement Learning agent.
We will tackle a concrete problem with modern libraries such as TensorFlow, TensorBoard, Keras, and OpenAI Gym. Create standard TF-Agents such as DQN, DDPG, TD3. The actual model used for predictions!.
Q-Learning with Q-Network or Deep Q Network (DQN) In the DQN, we replace the Q-Table with a neural network (Q-Network) that will learn to respond with the optimal action as we train it continuously with the explored states and their Q-Values. Furthermore, keras-rl works with OpenAI Gym out of the box. It will continue to be updated over time.
In particular, we first show that the recent DQN algorithm, which combines Q. Reinforcement Learning Toolbox™ provides functions and blocks for training policies using reinforcement learning algorithms including DQN, C, and DDPG. Memorize One of the challenges for DQN is that neural network used in the algorithm tends to forget the previous experiences as it overwrites them with new experiences.
As we enage in the environment, we will do a.predict () to figure out our next move (or move randomly). While the goal is to showcase TensorFlow 2.x, I will do my best to make DRL approachable as well, including a birds-eye overview of the field. Introduction to Deep Reinforcement Learning Shenglin Zhao Department of Computer Science & Engineering The Chinese University of Hong Kong.
Deep Q-networks March 03, 19. It was not previously known whether, in practice, such overestimations are common, whether they harm performance, and whether they can generally be prevented. As in our original Keras RL tutorial, we are directly given the input and output as numeric vectors.
So, there’s no need to employ more complex layers in our network other than fully connected layers. This algorithm was used by Google to beat humans at Atari games!. - DQN - Improvements to DQN - Learning from video input - Reproducing some of most popular RL solutions - Tuning parameters and general recommendations.
The main difference in this algorithm is the removal of the randomized back-propagation based updating of two networks A and B. 1) Create the environment, 2) specify policy representation, 3) create agent, 4) train agent, and 5) verify trained policy. The DQN family (Double DQN, Dueling DQN, Rainbow) is a reasonable starting point for discrete action spaces, and the Actor-Critic family (DDPG, TD3, SAC) would be a starting point for continuous spaces.
If you like this, please like my code on Github as well. DQN updates the Q-value function of a state for a specific action only. Use a function approximator to estimate the action-value function.
If γ (discount factor). Until now I have focused on on-policy algorithms - i.e. I've been experimenting with OpenAI gym recently, and one of the simplest environments is CartPole.
We can utilize most of the classes and methods corresponding to the DQN algorithm. The algorithm used to solve an RL problem is represented by an Agent. They must derive efficient.
Setup reinforcement learning agent:. Further, I recommend you really do try to implement your DQN from what I am writing here. Contributed Tutorials ».
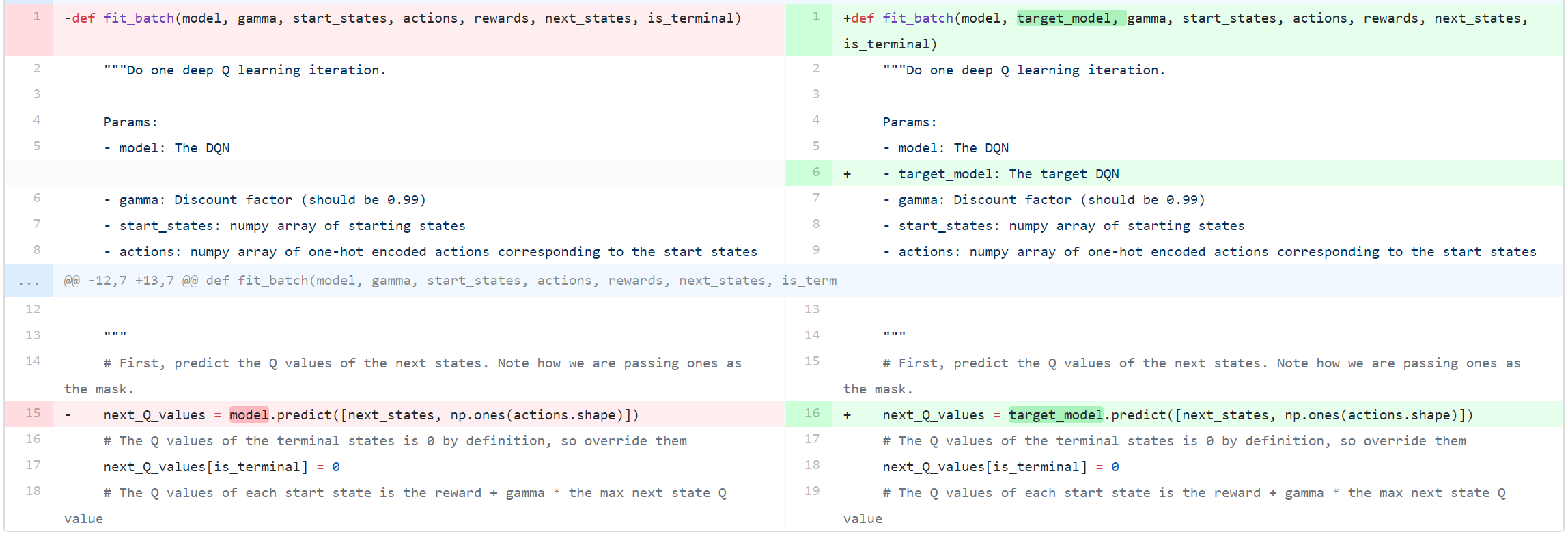
What we share below is a framework that can be extended and tweaked to obtain better performance. Compared with DQN, the main difference lies in the approaches to compute the target values. Value = reward + discount_factor * target_network.predict(next_state) argmax(online_network.predict(next_state)) the NN is fit to associate each state in the minibatch with the new Q values calculated for the actions taken.
The DQN I trained using the methods in this post. It reaches a score of 251. The workflow consists of the following steps:.
Reinforcement Learning (RL) Tutorial. So we can decompose Q(s,a) as the sum of:. Now, we will expand the Q-learning.
This course is a series of articles and videos where you'll master the skills and architectures you need, to become a deep reinforcement learning expert. To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task:. These values will be continuous float values, and they are directly our Q values.
By contrast, Q-learning has no constraint over the next action, as long as it maximizes the Q-value for the next state. Delayed Q-learning is an alternative implementation of the online Q-learning algorithm, with probably approximately correct (PAC) learning. I will be quoting it throughout.
Deep Q Networks introduction and realize it by coding. It was able to solve a wide range of Atari games (some to superhuman level) by combining reinforcement learning and deep neural networks at scale. This means that evaluating and playing around with different algorithms is easy.
You will learn how to implement one of the fundamental algorithms called deep Q-learning to learn its inner workings. Q Algorithm and Agent (Q-Learning) - Reinforcement Learning w/ Python Tutorial p.2 Welcome to part 2 of the reinforcement learning tutorial series, specifically with Q-Learning. In this tutorial, I am going to show you how to implement one of the most groundbreaking Reinforcement Learning algorithms — DQN with pixels.
The only actions are to add a force of -1 or +1 to the cart, pushing it left or right. Some of the hyperparameters used in the main.py script have been optainedvia Bayesian optimization with Scikit-Optimize. The agent has to decide between two actions - moving the cart left or right - so that the pole attached to it stays upright.
But as we’ll see, producing and updating a Q-table can become ineffective in big state space environments. However, there are certain additions we need to make for AirSim. This article is the third part of a series of blog post about Deep Reinforcement Learning.
Overview of Off-Policy Algorithms. Where, instead of defining a Q-table, neural network approximates the Q-values for each action and state. Thus, for training the network we need a place to store the game memory:.
An algorithm can run through the same states over and over again while experimenting with different actions, until it can infer which actions are best from which states. To solve such an issue, we can use a DQN algorithm. Algorithms that learn from data that were generated with the current policy.Off-policy algorithms, on the other hand, are able to learn from experiences (e.g.
Traditional learning algorithms usually have much fewer learnable parameters than deep learning algorithms and have much less learning capacity. Last time, we learned about Q-Learning:. In this tutorial, I will give an overview of the TensorFlow 2.x features through the lens of deep reinforcement learning (DRL) by implementing an advantage actor-critic (C) agent, solving the classic CartPole-v0 environment.
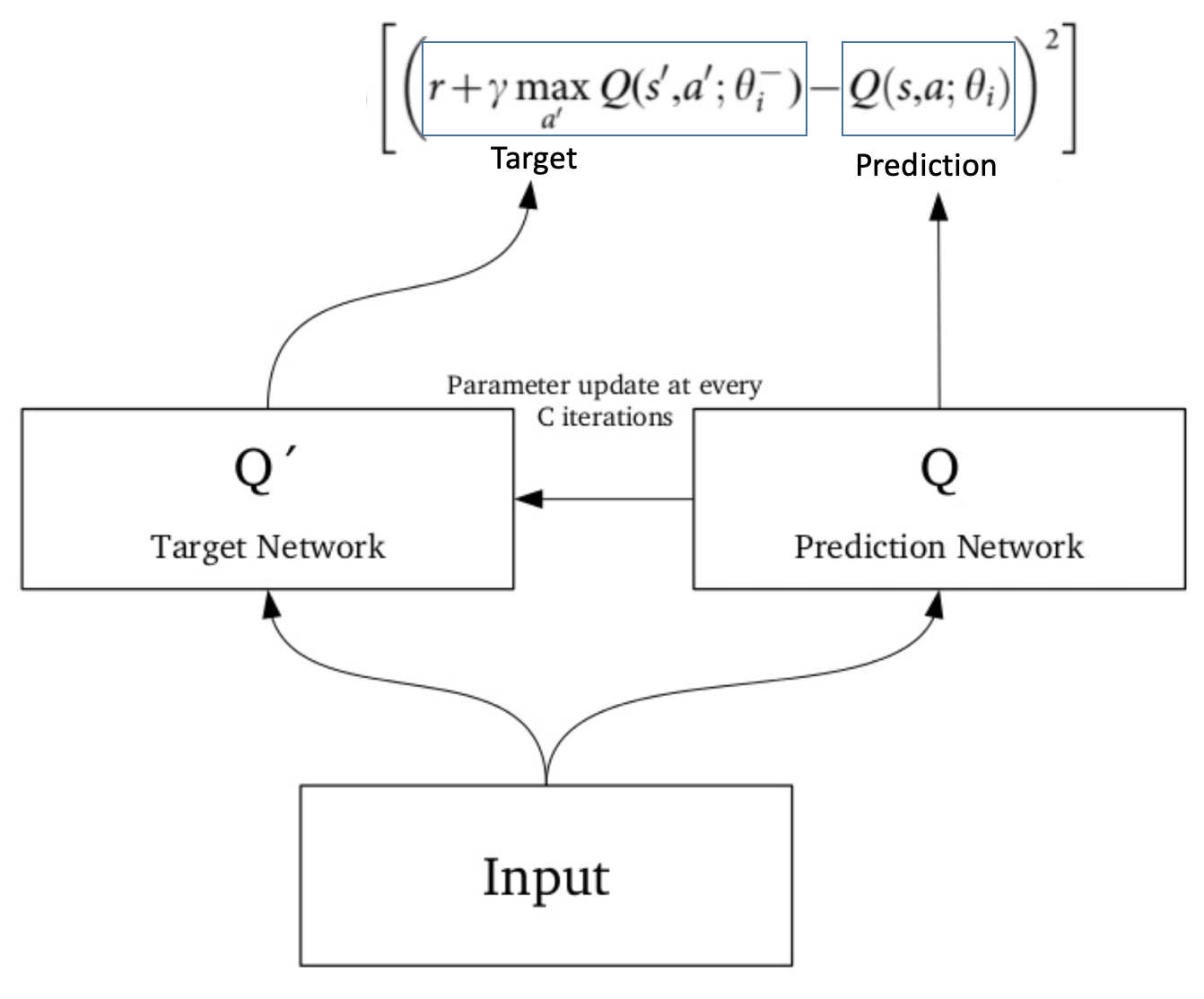
The results on the left below show the performance of DQN and the algorithm hierarchical-DQN from Kulkarni et al. Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning. The popular Q-learning algorithm is known to overestimate action values under certain conditions.
We will be using Deep Q-learning algorithm. This is a major consideration for selecting a reinforcement learning algorithm. You can use these policies to implement controllers and decision-making algorithms for complex systems such as robots and autonomous systems.
Learn to apply Reinforcement Learning and Artificial Intelligence algorithms using Python, Pytorch and OpenAI Gym. Deep Q-network (DQN) •An artificial agent for general Atari game playing –Learn to master 49 different Atari games directly from game screens –Beat the best performing learner from the same domain in 43 games –Excel human expert in 29 games. The environment uses information about the agent’s current state and action as input, and returns the agent’s reward and its next state as output.
Disclaimer# This is still in active development. This algorithm was later modified clarification needed in 15 and combined with deep learning, as in the DQN algorithm, resulting in Double DQN, which outperforms the original DQN algorithm. The problem consists of balancing a pole connected with one joint on top of a moving cart.
Ta = r + GAMMA * pTarget_i numpy.argmax(p_i) The Deep Reinforcement Learning with Double Q-learning 1 paper reports that although Double DQN (DDQN) does not always improve performance, it substantially benefits the stability of learning. You'll build a strong professional portfolio by implementing awesome agents with Tensorflow that learns to play Space invaders, Doom, Sonic the hedgehog and more!. Q-learning is a policy based learning algorithm with the function approximator as a neural network.
Learning algorithms assume the data samples to be independent, while in reinforcement learning one typically encounters sequences of highly correlated states. You can also read this article on our Mobile APP. This post uses Deep Q Networks to introduce off-policy algorithms.
Till then, you can refer to this paper on a survey of reinforcement learning algorithms. 01 July 16 on tutorials.
Demystifying Deep Reinforcement Learning Computational Neuroscience Lab

Deep Reinforcement Learning 1 Deep Q Network Dqn Programmer Sought
Beyond Dqn A3c A Survey In Advanced Reinforcement Learning
Project Inria Fr Paiss Files 18 07 Munos Off Policy Drl Pdf

David Silver Google Deepmind Deep Reinforcement Learning Synced
Github Higgsfield Rl Adventure 2 Pytorch0 4 Implementation Of Actor Critic Proximal Policy Optimization Acer Ddpg Twin Dueling Ddpg Soft Actor Critic Generative Adversarial Imitation Learning Hindsight Experience Replay

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
3

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
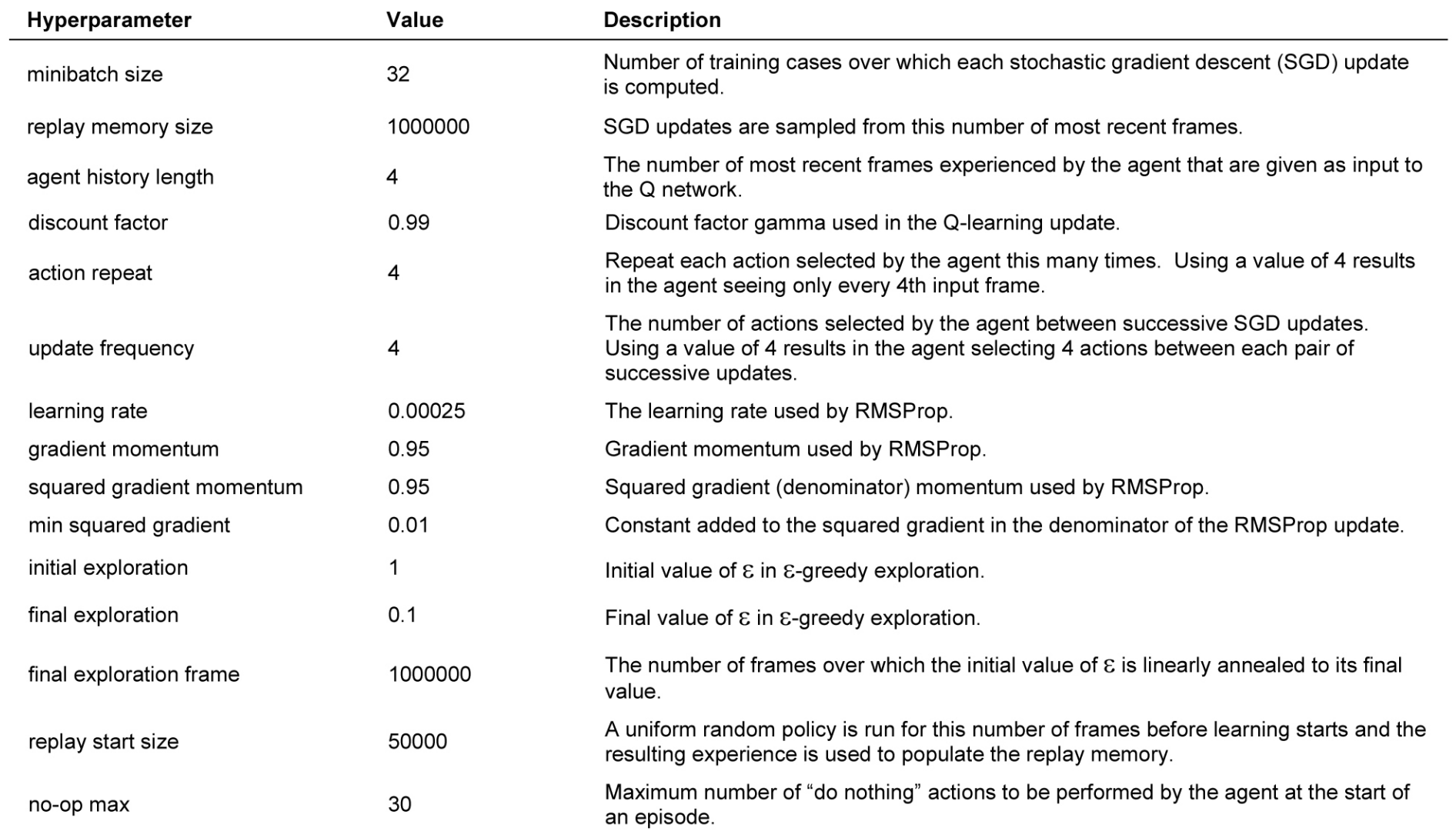
Beat Atari With Deep Reinforcement Learning Part 1 Dqn By Adrien Lucas Ecoffet Becoming Human Artificial Intelligence Magazine

Google Ai Blog An Optimistic Perspective On Offline Reinforcement Learning
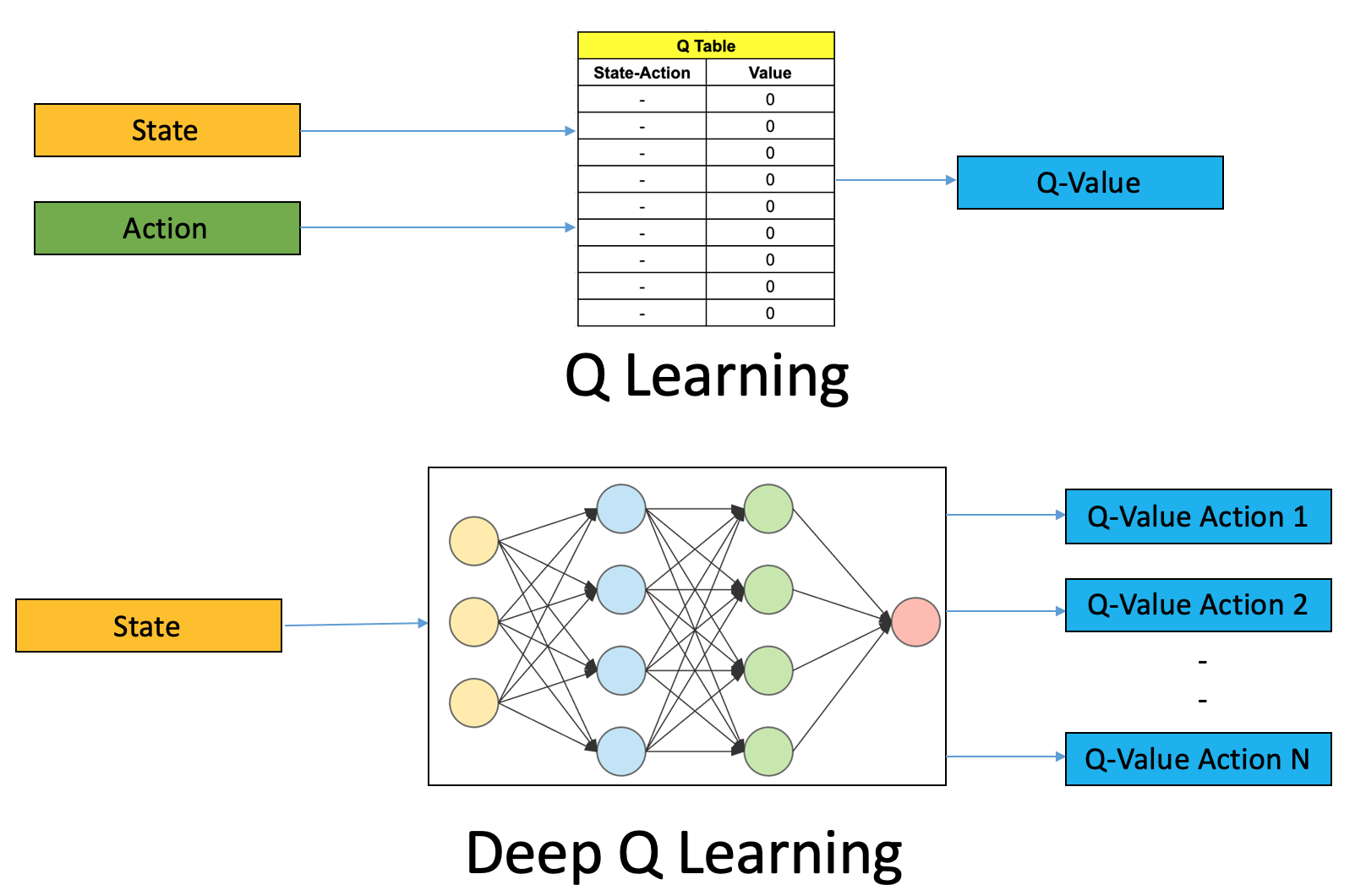
Deep Q Learning An Introduction To Deep Reinforcement Learning

Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed
Application Of Deep Neural Network And Deep Reinforcement Learning In Wireless Communication

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Bayesian Deep Reinforcement Learning Via Deep Kernel Learning Atlantis Press
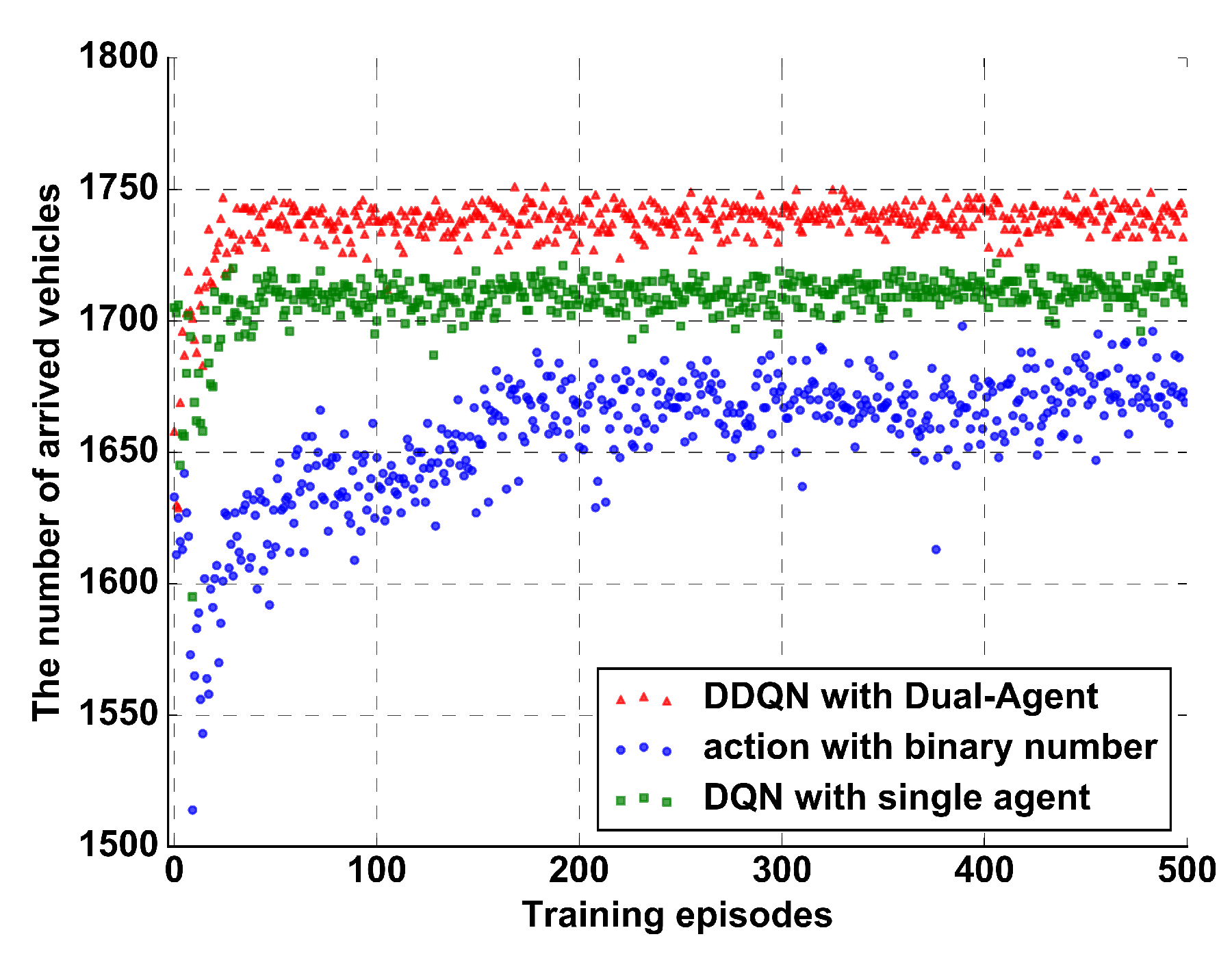
Applied Sciences Free Full Text Double Deep Q Network With A Dual Agent For Traffic Signal Control Html
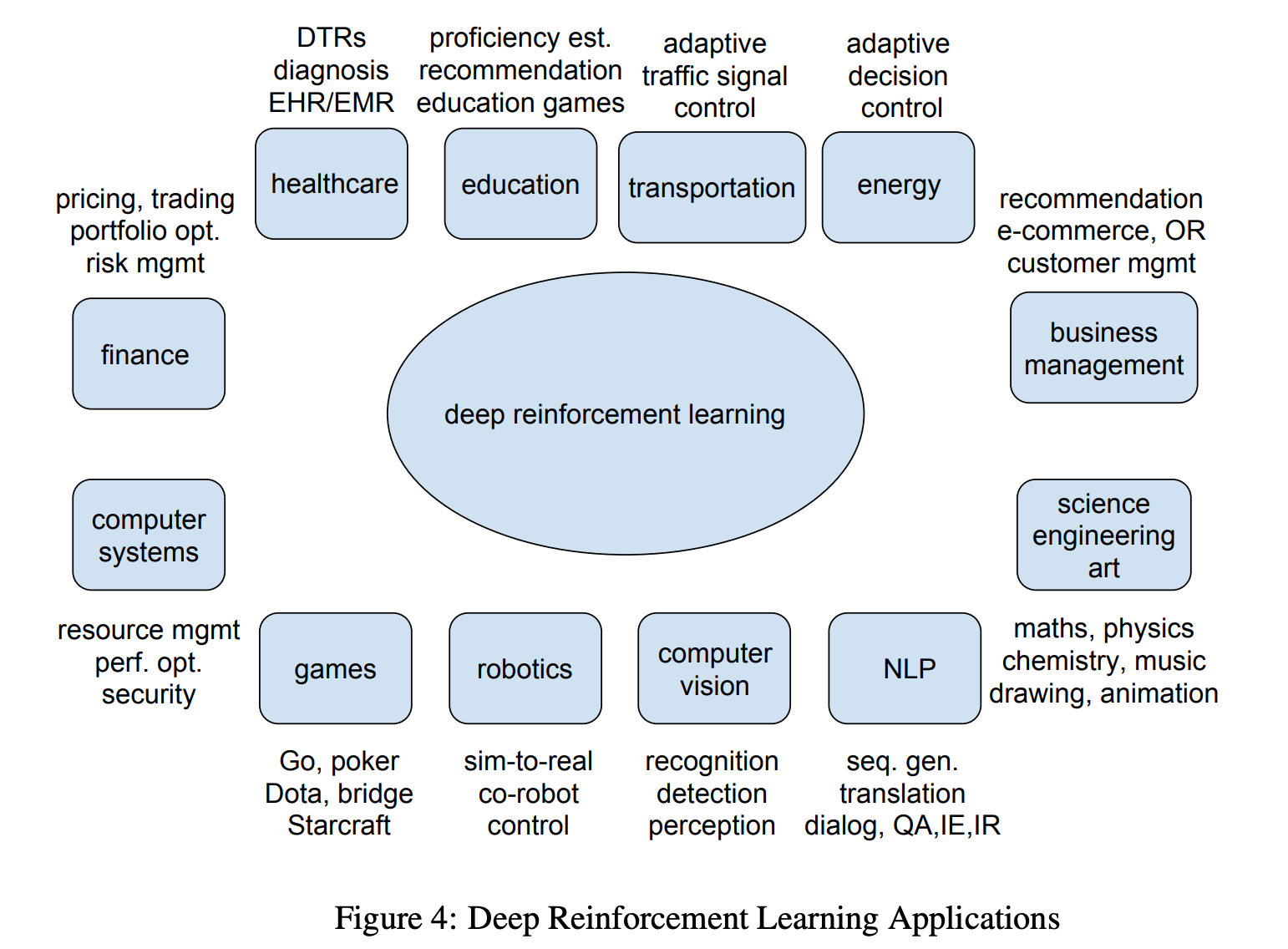
Deep Q Learning An Introduction To Deep Reinforcement Learning

Agents Reinforcement Learning Coach 0 12 0 Documentation

A Long Peek Into Reinforcement Learning

Reinforcement Learning For An Inverted Pendulum With Image Data Video Matlab

What Are Possible Reasons Why Q Loss Is Not Converging In Deep Q Learning Algorithm

Policy Gradient Algorithms

David Silver Google Deepmind Deep Reinforcement Learning Synced

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Reinforcement Learning W Keras Openai Actor Critic Models Deep Learning Learning Reinforcement
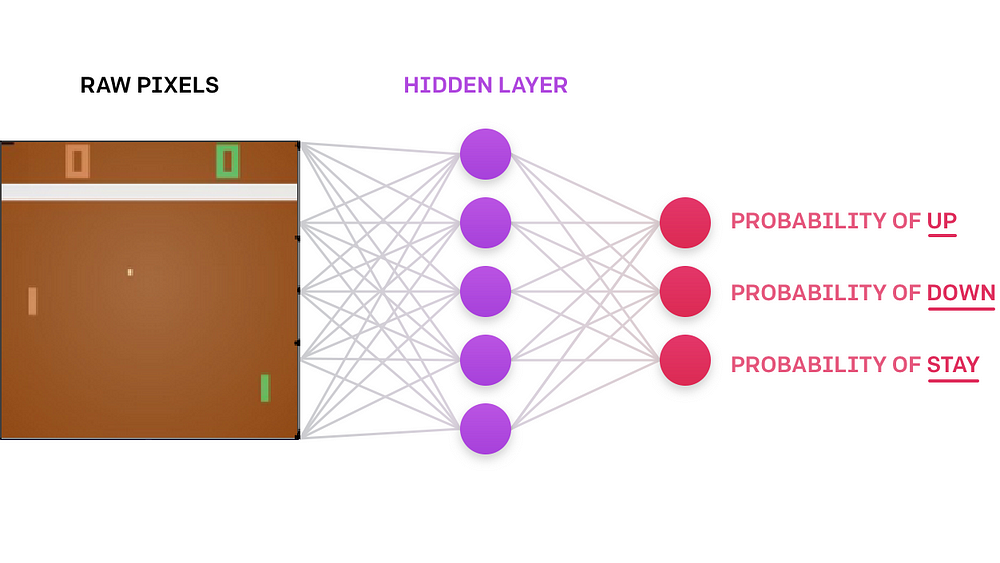
A I Learns To Play Pong With Dqn Mc Ai

Deep Q Learning 101 Datahubbs

Rllib Algorithms Ray V1 1 0 Dev0
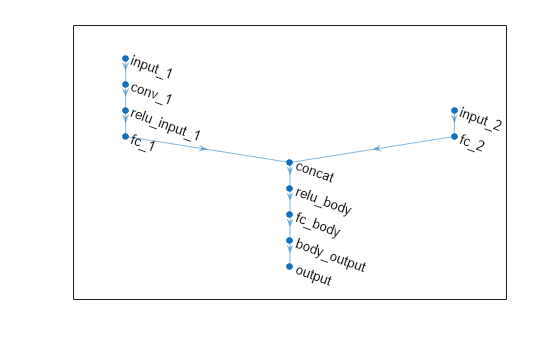
Deep Q Network Reinforcement Learning Agent Matlab

Python Lessons

Balancing A Cartpole System With Reinforcement Learning A Tutorial Deepai

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Deep Q Learning Part2 Double Deep Q Network Double Dqn By Amber Medium

6 Dqn Using Tensorflow Reinforcement Learning Eng Tutorial Youtube
3
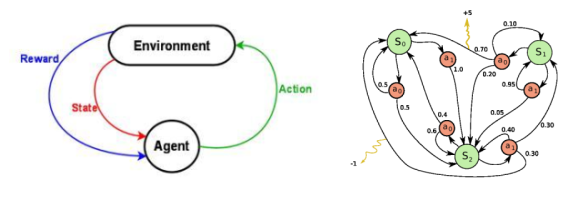
Demystifying Deep Reinforcement Learning Computational Neuroscience Lab
Arxiv Org Pdf 1701
Multiagent Cooperation And Competition With Deep Reinforcement Learning
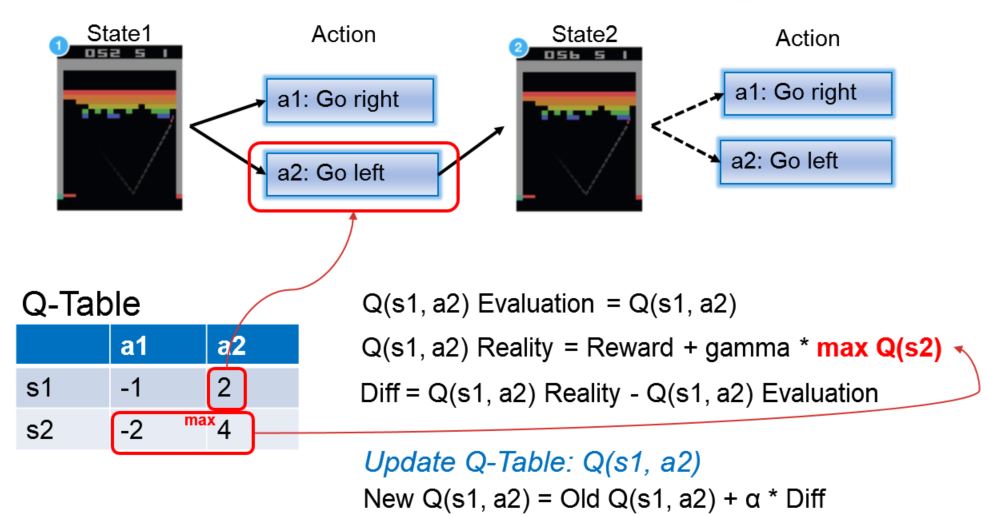
Reinforcement Learning Get Started To Learn Dqn For Reinforcement Learning

Python Programming Tutorials

Openai Baselines Dqn
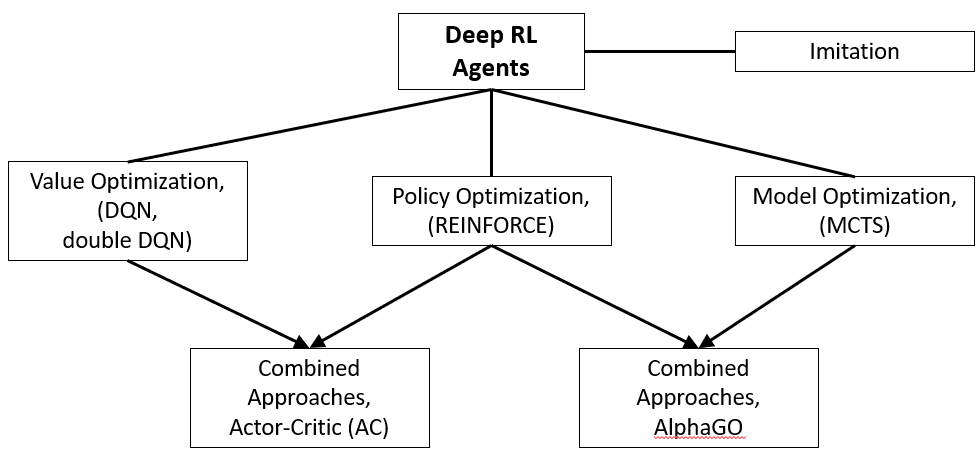
Reinforcement Learning Agents Beyond Dqn Mc Ai
Project Inria Fr Paiss Files 18 07 Munos Off Policy Drl Pdf

Q Tbn 3aand9gctw4qrjjlye9llax6ryad9kt8bngfsbgyffeg Usqp Cau
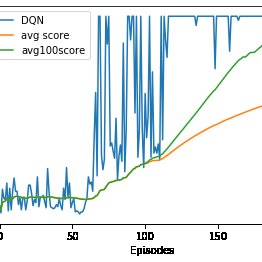
Pdf Balancing A Cartpole System With Reinforcement Learning A Tutorial
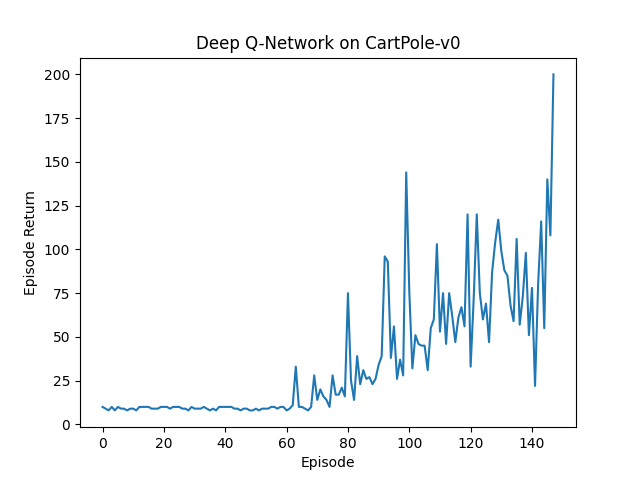
Train A Deep Q Network With Swift For Tensorflow S4tf Endtoend Ai

Dqn Deep Q Network

Q Tbn 3aand9gcq0j94bxkaygc0fc0b5mnjpg32oey11kbyuma Usqp Cau
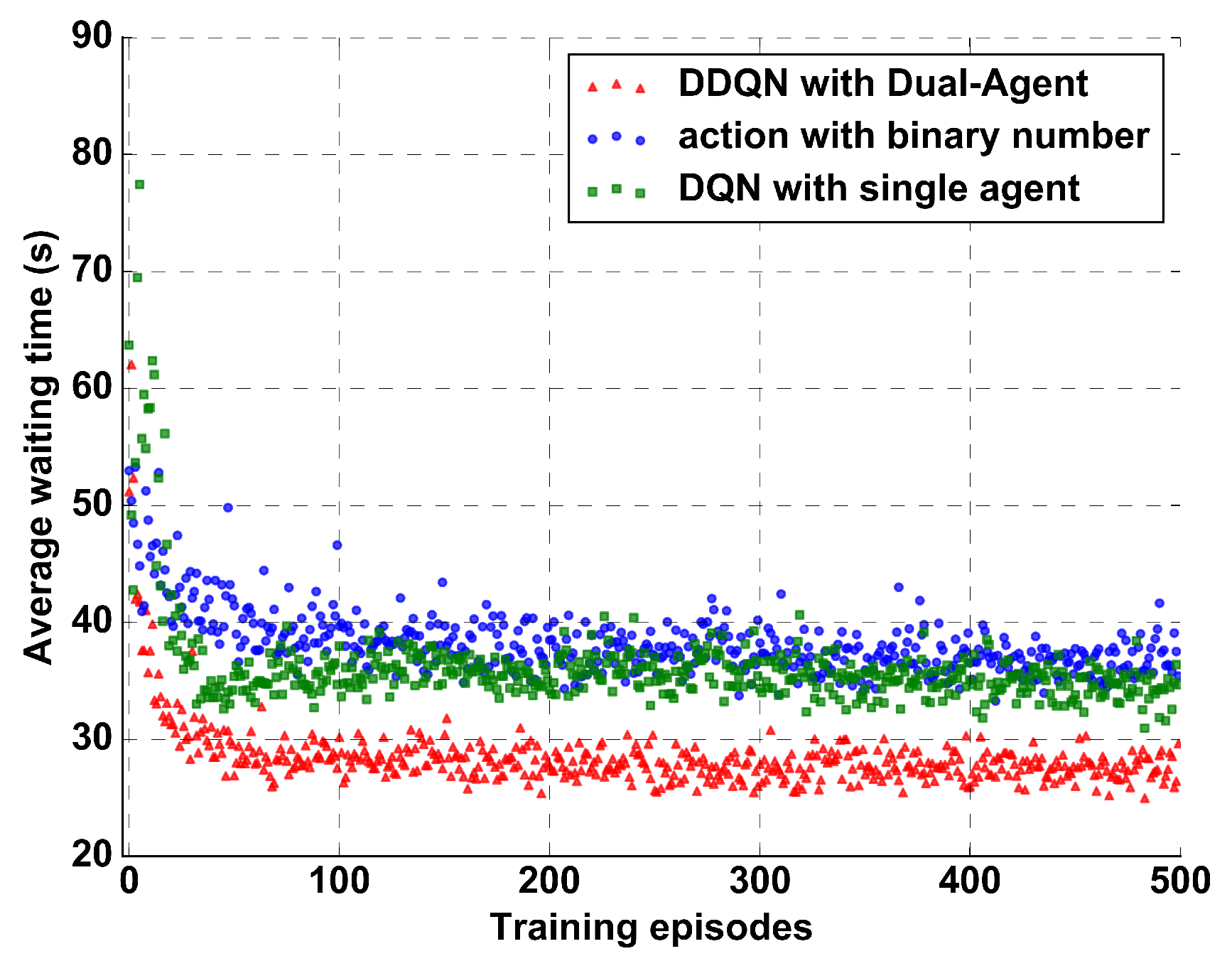
Applied Sciences Free Full Text Double Deep Q Network With A Dual Agent For Traffic Signal Control Html
Beat Atari With Deep Reinforcement Learning Part 2 Dqn Improvements By Adrien Lucas Ecoffet Becoming Human Artificial Intelligence Magazine

Deep Q Learning W Dqn Reinforcement Learning P 5 Youtube
Q Learning And Dqn Efavdb
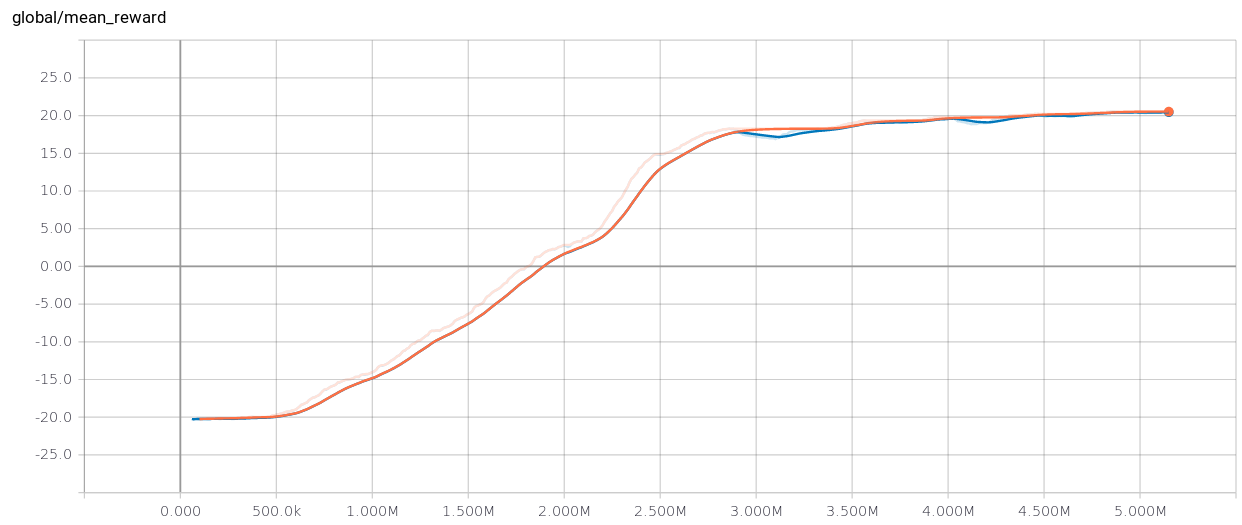
Performance Of Dqn Algorithm Avg100score Is The Average Of Last 100 Download Scientific Diagram
Q Tbn 3aand9gct9nay65nz9jnygtqujzpt3wzpfmhjxi9hohz7mq0n28trmcynw Usqp Cau
Deep Q Learning An Introduction To Deep Reinforcement Learning

Reinforcejs Gridworld With Dynamic Programming
Python Programming Tutorials

Introduction To Reinforcement Learning

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
3
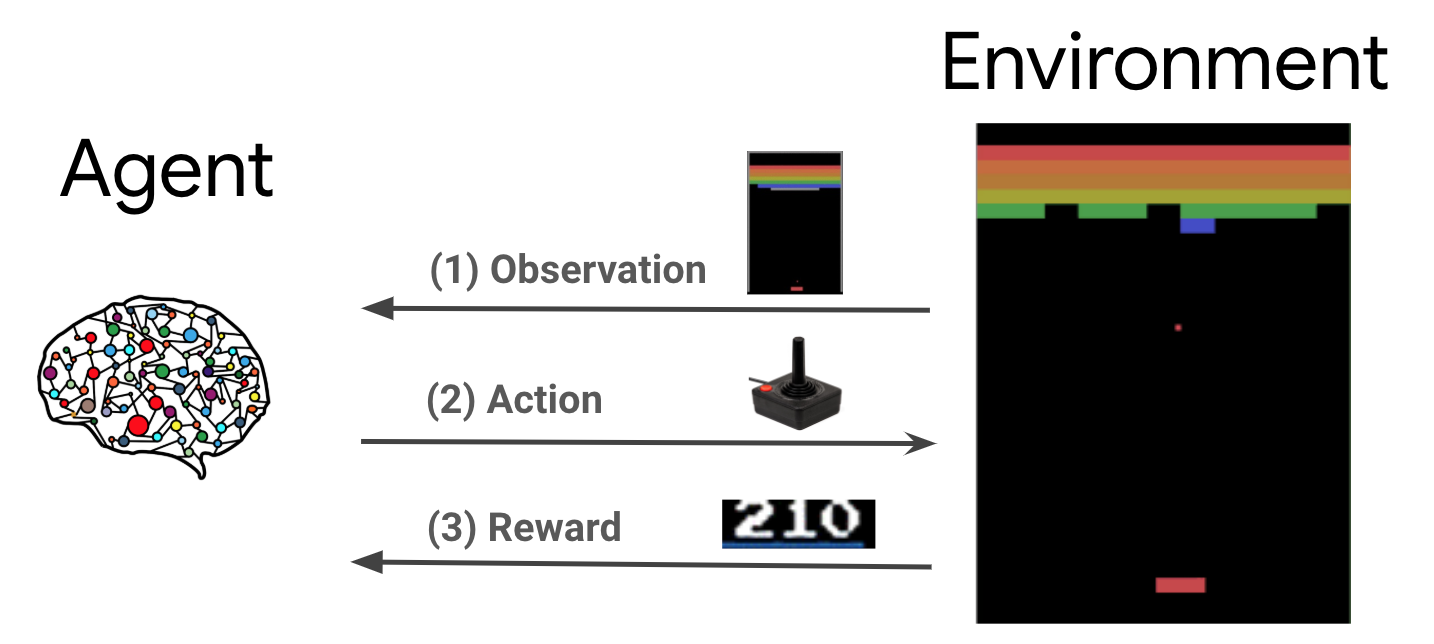
Introduction To Rl And Deep Q Networks Tensorflow Agents

Openai Baselines Dqn

Pytorch Reinforcement Learning Teaching Ai How To Play Flappy Bird Toptal
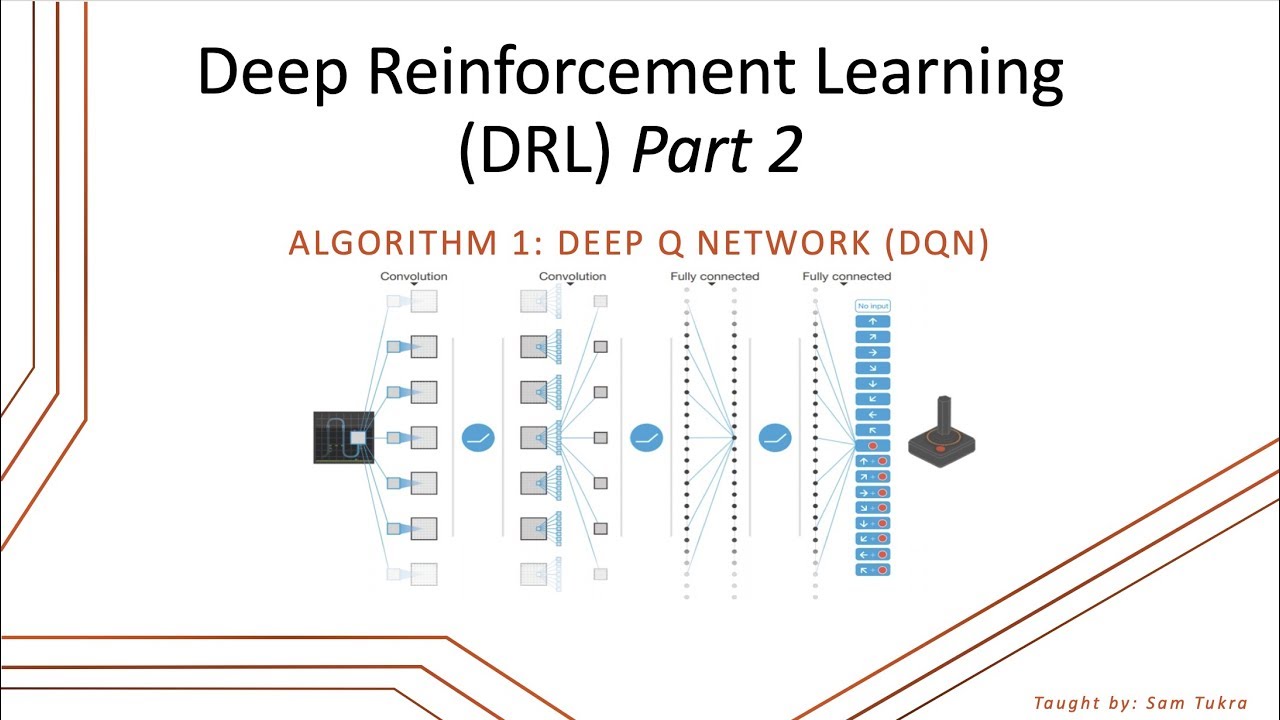
Deep Reinforcement Learning Dqn Deep Q Networks P 2 Youtube
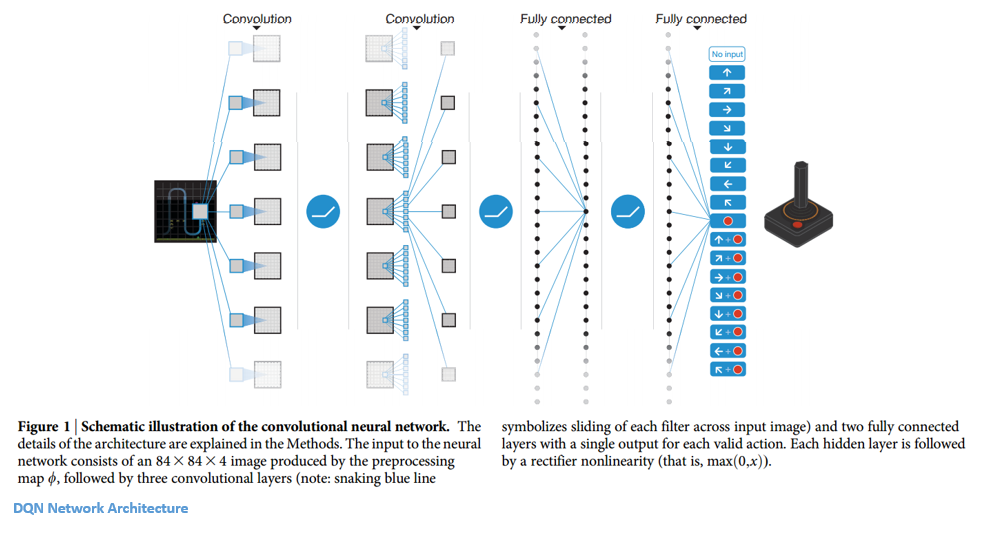
Deep Learning Research Review Reinforcement Learning

Torch Dqn Algorithm Programmer Sought

Deep Q Network Dqn Ii Experience Replay And Target Networks By Jordi Torres Ai Aug Towards Data Science

Double Q Reinforcement Learning In Tensorflow 2 Adventures In Machine Learning
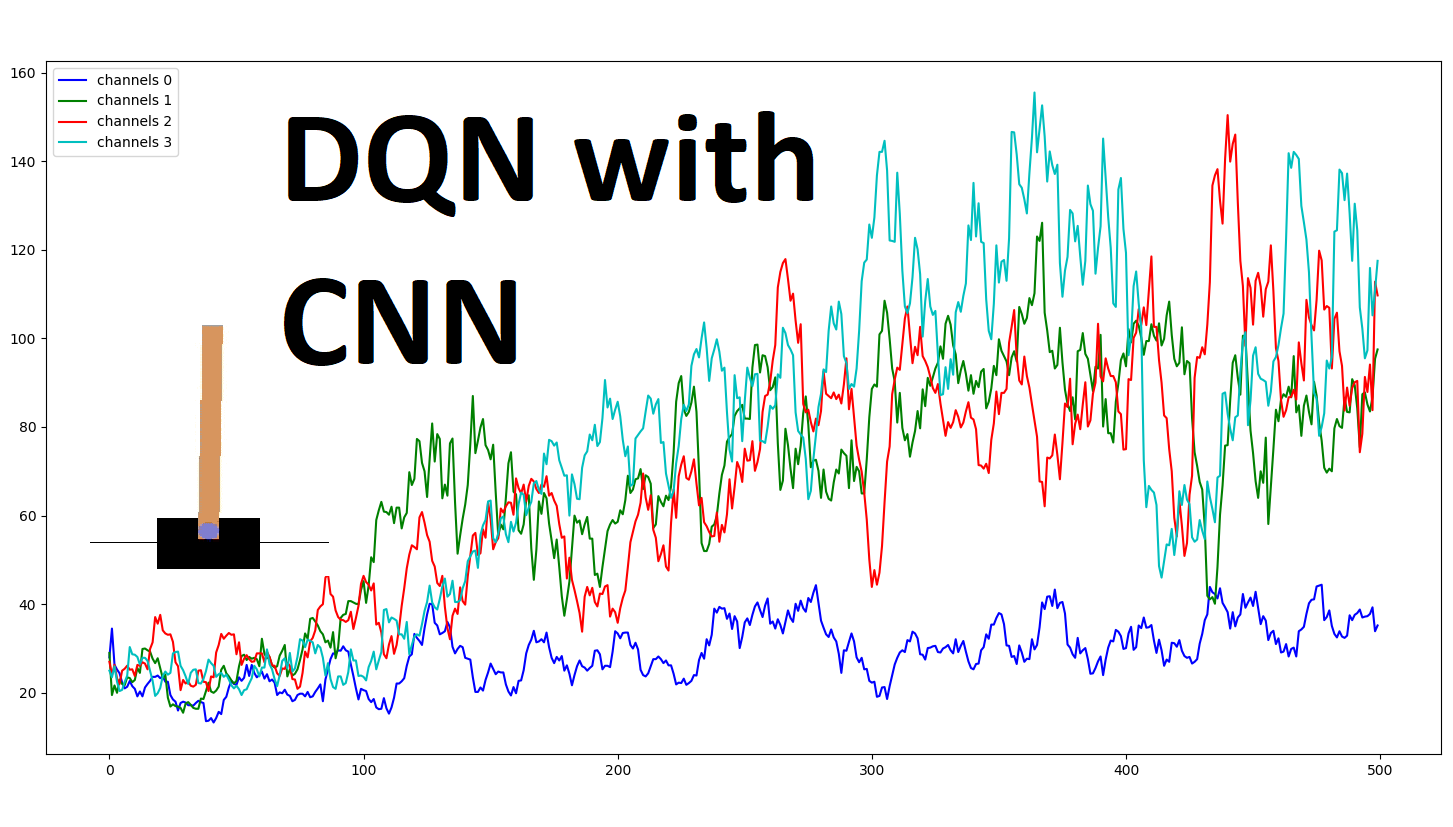
Deep Q Network With Convolutional Neural Networks By Rokas Balsys Analytics Vidhya Medium

Building A Powerful Dqn In Tensorflow 2 0 Explanation Tutorial By Sebastian Theiler Analytics Vidhya Medium

Dqn Reward Fluctuates After Converging Reinforcementlearning

Dqn Deep Q Network

Pytorch Reinforcement Learning Teaching Ai How To Play Flappy Bird Toptal
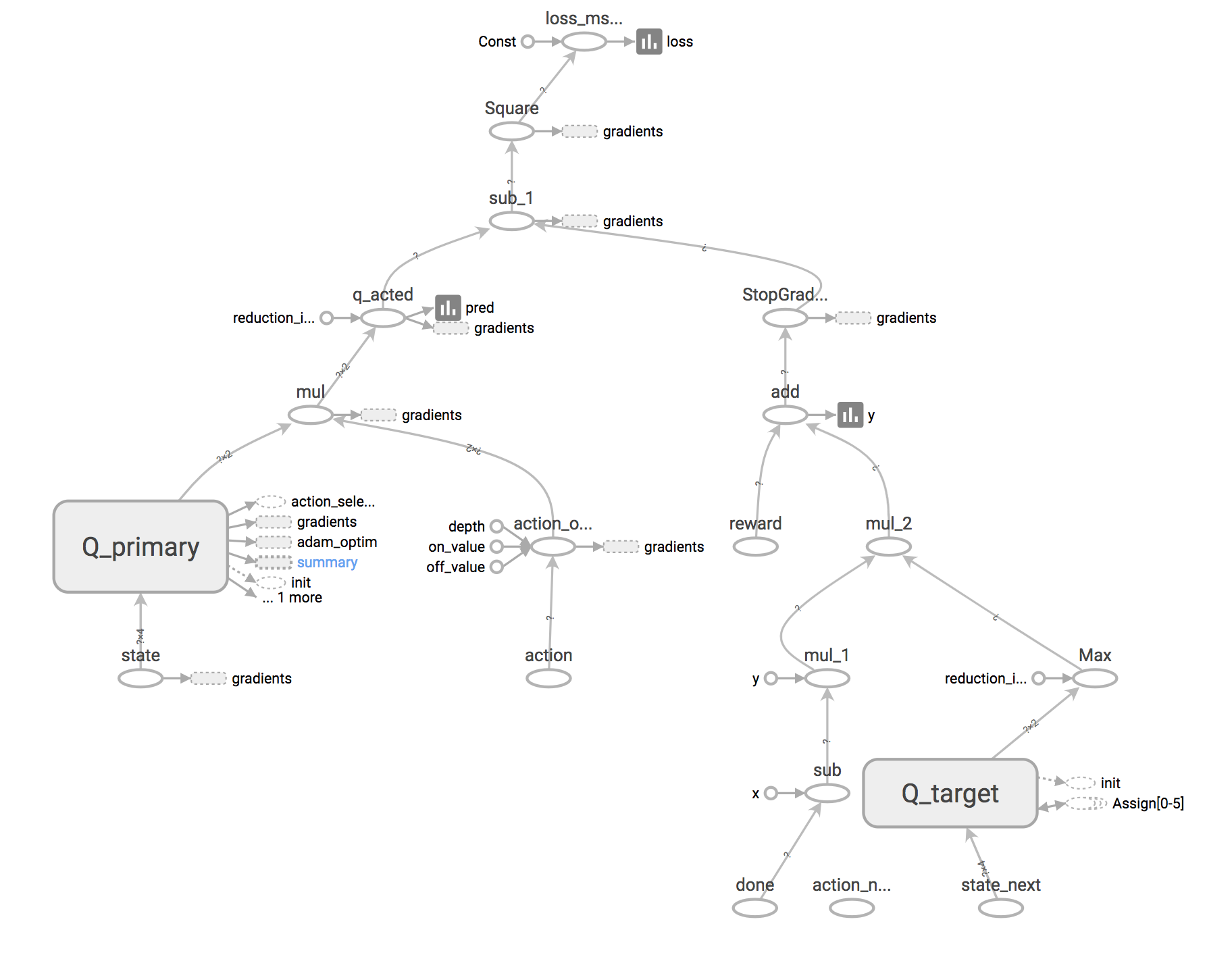
Implementing Deep Reinforcement Learning Models With Tensorflow Openai Gym

Dynamicwebpaige 127 0 0 1 I M Absolutely In Love With The Mathematical And Code Annotations For This Blog Post On Reinforcement Learning Building A Powerful Dqn In Tensorflow 2 0

Reinforcement Learning W Keras Openai Actor Critic Models Data Science Learning Deep Learning

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium

Reinforcement Learning Part 2 Getting Started With Deep Q Networks Novatec

Reinforcement Learning Dqn Tutorial Pytorch Tutorials 1 6 0 Documentation
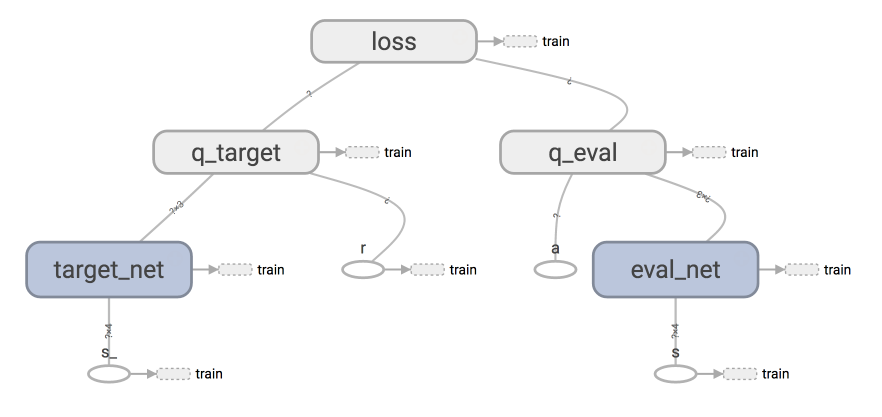
Xs Code

Train A Deep Q Network With Tf Agents Tensorflow Agents
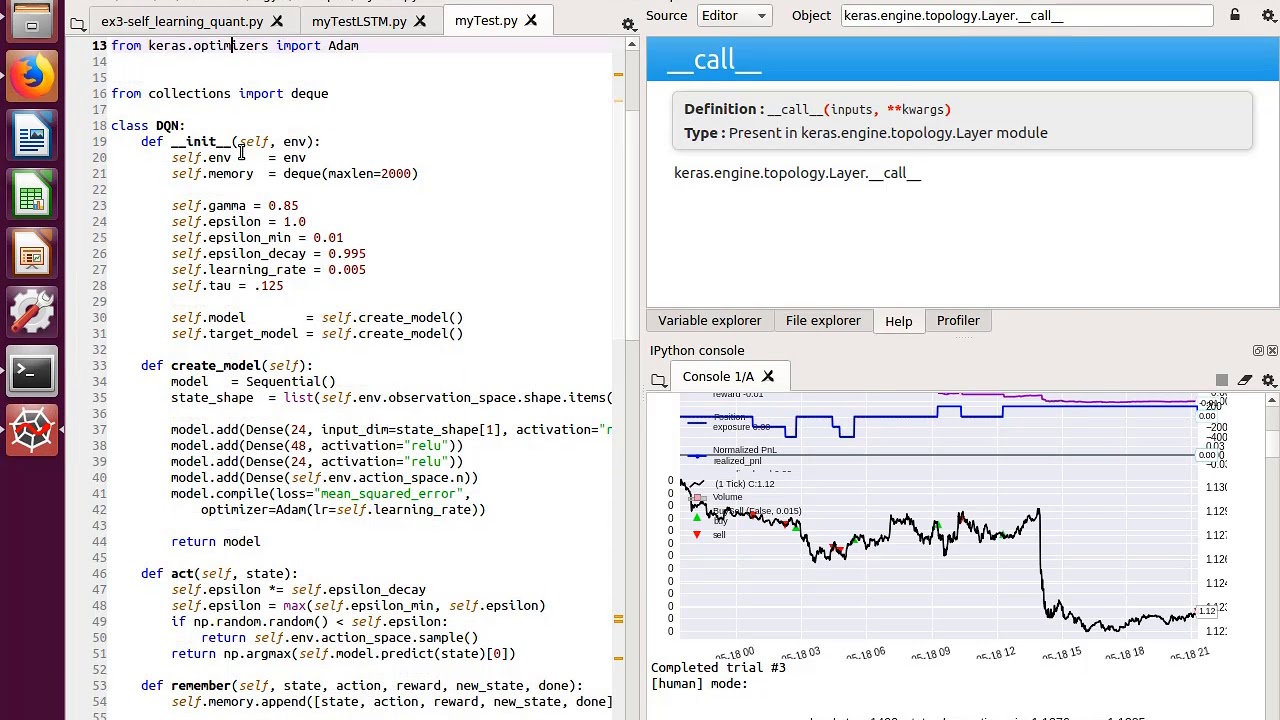
Tutorial Deep Reinforcement Learning For Algorithmic Trading In Python Youtube

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium

What Are Possible Reasons Why Q Loss Is Not Converging In Deep Q Learning Algorithm
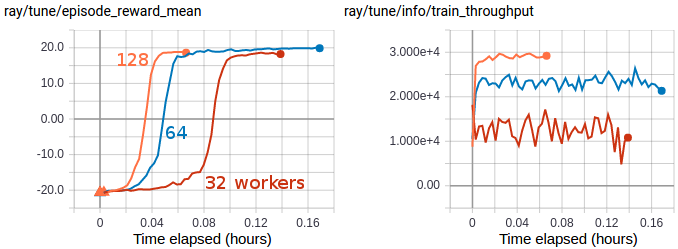
Rllib Algorithms Ray V1 1 0 Dev0

Google Ai Blog An Optimistic Perspective On Offline Reinforcement Learning

Alexandr Kalinin Dqn Adventure From Zero To State Of The Art T Co 4f13idvuyz An Easy To Follow Step By Step Deep Q Learning Tutorial With Clean Readable Pytorch Code T Co Mrdvs3102p

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium
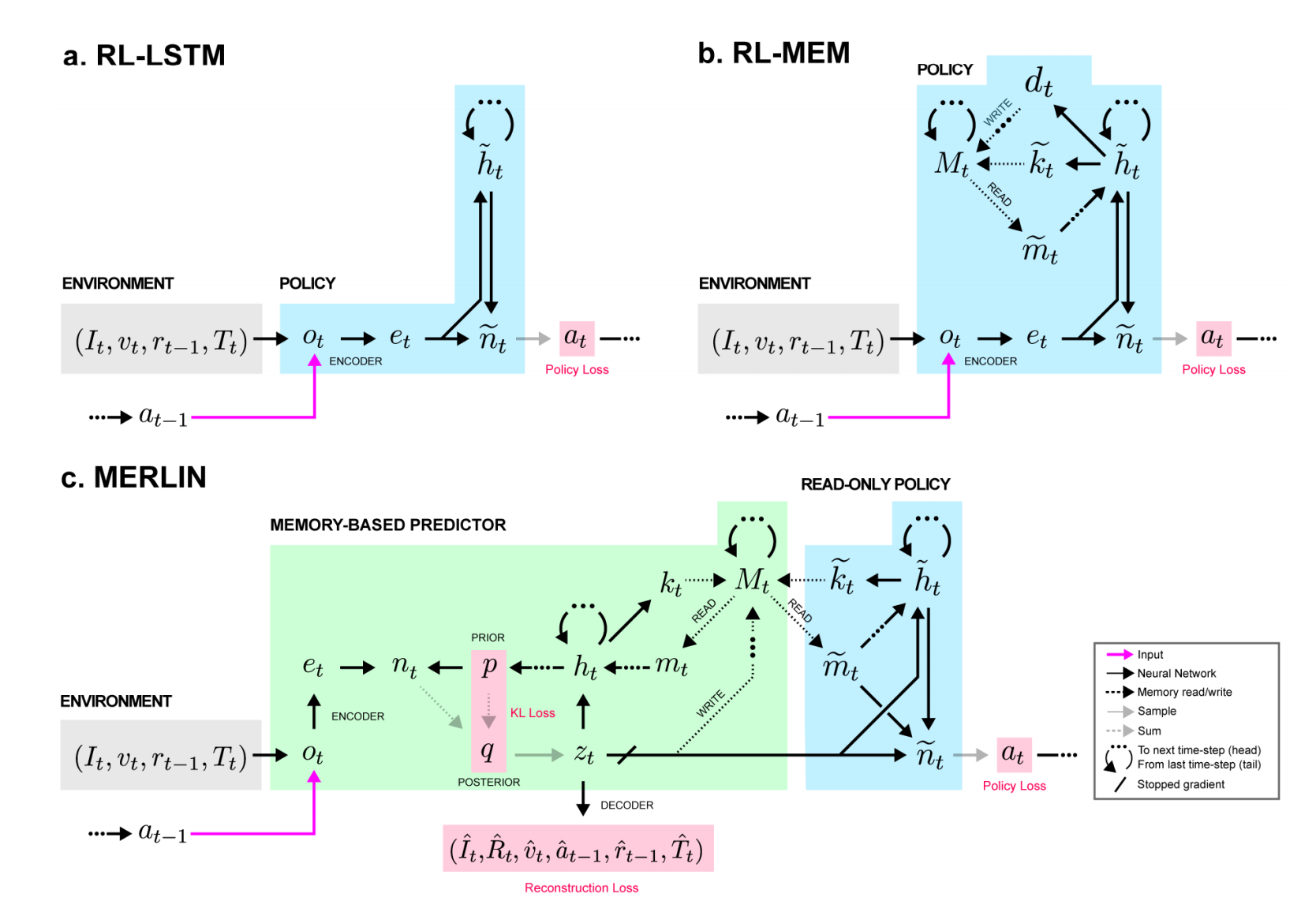
Beyond Dqn A3c A Survey In Advanced Reinforcement Learning By Joyce Xu Towards Data Science

The Difference Between Double Dqn Algorithm Target Network And Predict Network Programmer Sought

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium

Understanding Dqn Her Deep Robotics

Deep Reinforcement Learning With Tensorflow 2 1 Roman Ring

Python Lessons
Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed

Q Tbn 3aand9gctgja0o0eorx3l8bdrxxzegvll2dg Lllseta Usqp Cau

Understanding Dqn Her Deep Robotics



