Dqn Algorithm Pseudocode
Http Proceedings Mlr Press V48 Mniha16 Pdf
Q Tbn 3aand9gcrzxn1ubg5gpijcicluwhglucozqlurydhryo8tuj99gt8sawps Usqp Cau
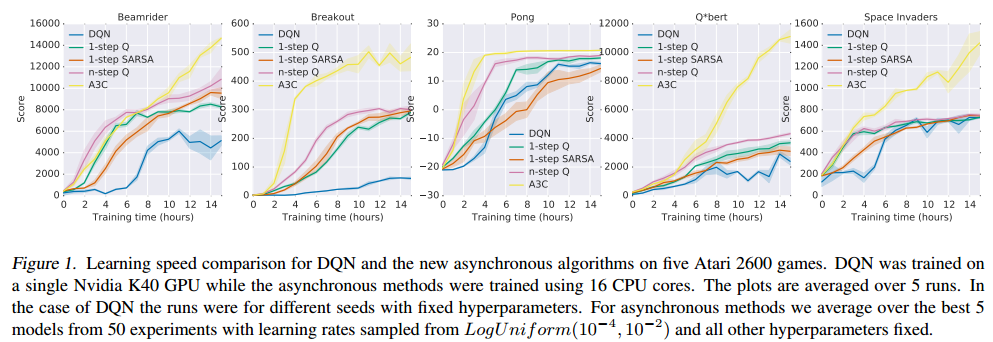
Asynchronous Methods For Deep Reinforcement Learning The Morning Paper

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science
Q Tbn 3aand9gct9nay65nz9jnygtqujzpt3wzpfmhjxi9hohz7mq0n28trmcynw Usqp Cau
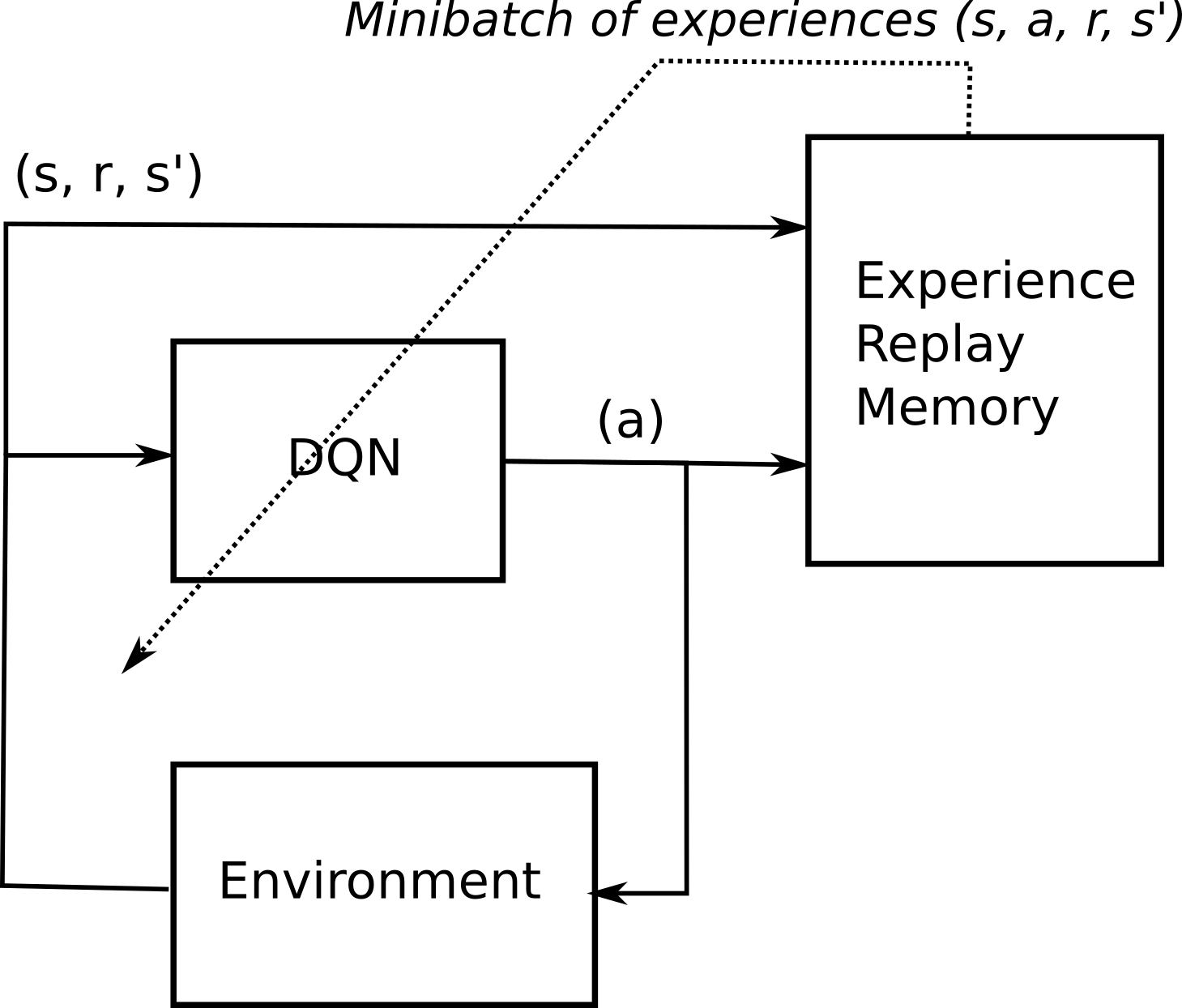
Deep Reinforcement Learning
Implementation Dueling DQN (aka DDQN) Theory.

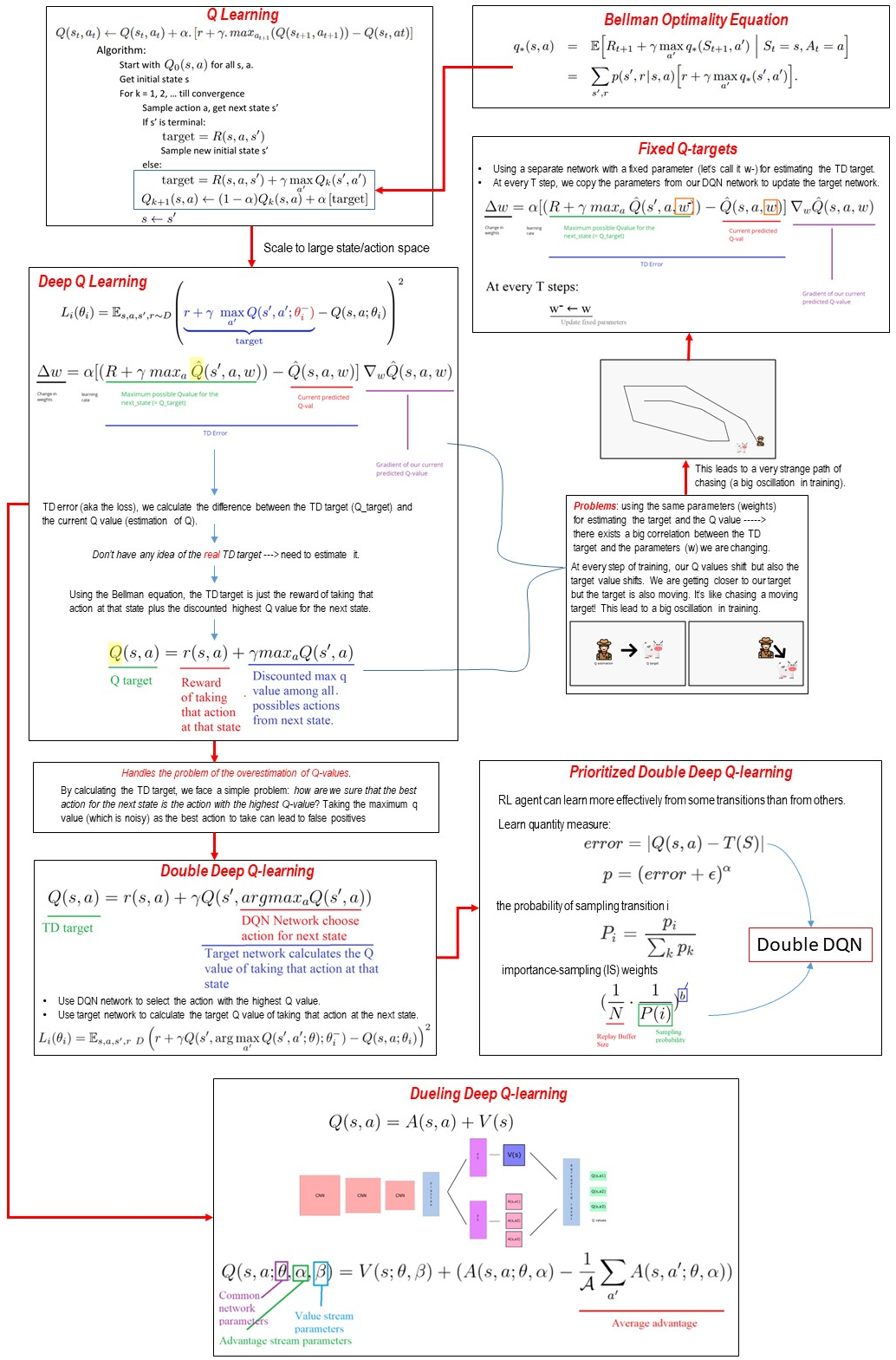
Dqn algorithm pseudocode. The deep Q-network (DQN) algorithm is a model-free, online, off-policy reinforcement learning method. The rest of the algorithm is designed to support these steps. Normalized Advantage Functions + no change to algorithm + just as efficient as Q-learning - loses representational power.
The pseudocode of the DQN algorithm is described as follows:. In computer science, pseudocode is a plain language description of the steps in an algorithm or another system. Memory and time Finiteness is not enough if we have to wait too much to obtain the result Example:.
We can summarize the previous explanations with this pseudocode for the basic DQN algorithm that will guide our implementation of the algorithm:. We propose two algorithms. Remember that Q-values correspond to how good it is to be at that state and taking an action at that state Q(s,a).
DQN (policy, env, gamma=0.99, learning. An algorithm which produces a Q-table that an agent uses to find the best action to take given a state. Against the use of pseudocode for describing algorithms in educational or reference materials, preferring instead.
DeepMind’s deep Q-network (DQN) algorithm (13, 15) 27 is the first successful algorithm of DRL for combining DL and RL. It is summarized by the following pseudocode:. It is summarized by the following pseudocode:.
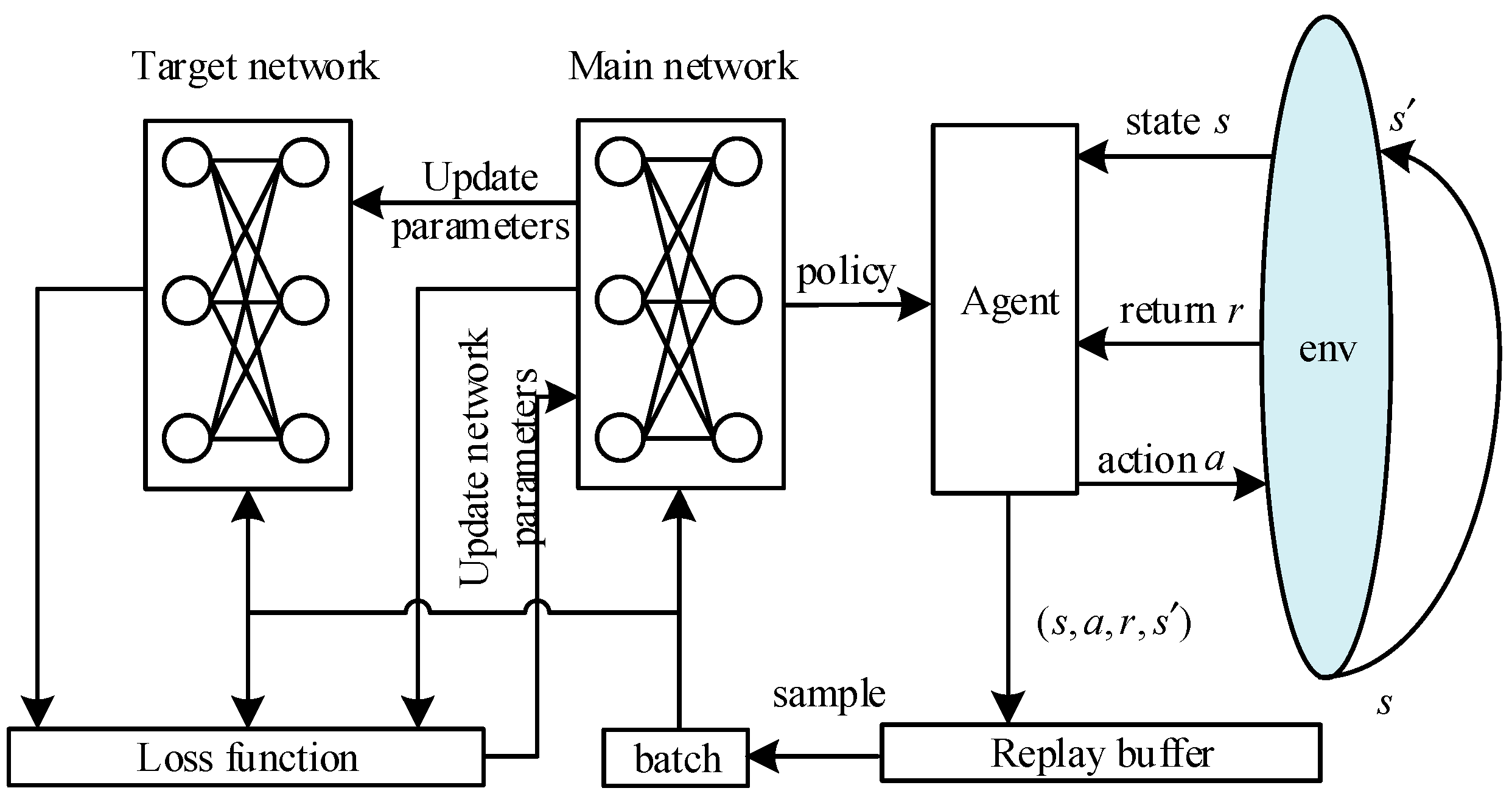
In the beginning, we need to create the main network and the target networks, and initialize an empty replay memory D. This tutorial shows how to use PyTorch to train a Deep Q Learning (DQN) agent on the CartPole-v0 task from the OpenAI Gym. Now, we can discuss the basic DQN algorithm.
When the callback inherits from BaseCallback, you will have access to additional stages of the training (training start/end), please read the. If γ (discount factor). Process 1 and process 3 run at the same speed, process 2 is slow •Fitted Q-iteration:.
For more information on Q-learning, see Q-Learning Agents. Q-Learning is an Off-Policy algorithm for Temporal Difference learning. The theory of reinforcement learning provides a normative account deeply rooted in psychological and neuroscientific perspectives on animal behaviour, of how agents may optimize their control of an environment.
So we can decompose Q(s,a) as the sum of:. The rest of the algorithm is designed to support these steps. (DQN) and Deep Deterministic Policy Gradient (DDPG), and we evaluate these on the Arcade Learning Environment.
However, this proposed method is a tabular/matrix way, we have discussed such drawbacks in part 1.Based on the same reasons, we need to go deep now. A pseudo-code uses natural language or compact mathematical notation to write algorithms. Important settings of the DTORA algorithm.
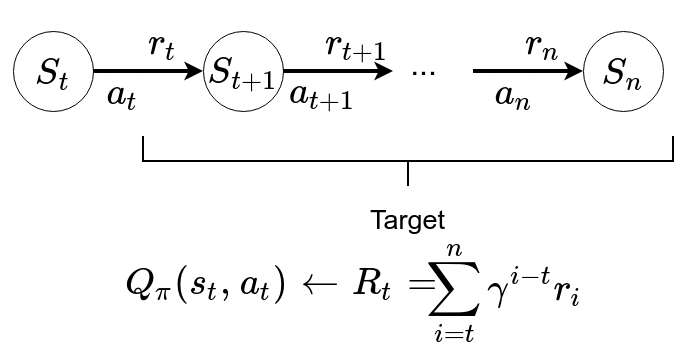
First, it randomly accesses a batch of unlabeled instances, using the DQN model to assign confidence scores (qvalue) for each instance. This post begins by an introduction to reinforcement learning and is then followed by a detailed explanation of DQN. Q n e w ( s t , a t ) ← Q ( s t , a t ) ⏟ old value + α ⏟ learning rate ⋅ ( r t ⏟ reward + γ ⏟ discount factor ⋅ max a Q ( s t + 1 , a ) ⏟ estimate of optimal future value ⏟ new value (temporal difference target) − Q ( s t , a t ) ⏟ old value ) ⏞ temporal difference.
Initialize value network \(Q_{\theta}\) with random weights. Having said that I don't think the git code that you linked does what you expect (Why do you have an ES module?. Delayed Q-learning is an alternative implementation of the online Q-learning algorithm, with probably approximately correct (PAC) learning.
The action is passed to the emulator and modifies its internal state and the game score. By contrast, Q-learning has no constraint over the next action, as long as it maximizes the Q-value for the next state. At each time-step t the agent selects an action at from a set of legal game actions A = {1,.,K}.
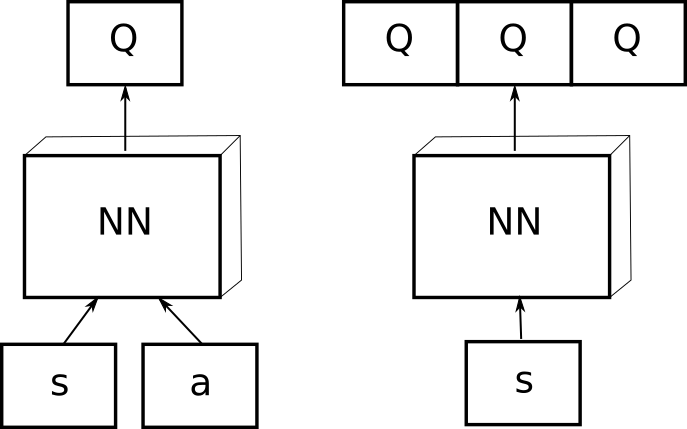
We’re given a neural network that acts as a function approximation of the value of a particular state input (this is why Q-Learning is referred to as a value-based method). Last time, we learned about Q-Learning:. The basic idea is this (again, I’ll save the theory for a later post):.
In this post, therefore, I would like to give a guide to a subset of the DQN algorithm. DQN is the non-central trimmed mean of differences between perfect match and mismatch intensities with quantile normalization. Thus, we do not use a replay memory and rely on parallel actors employing different exploration policies to perform the stabilizing role undertaken by experience replay in the DQN training algorithm.
It was not previously known whether, in practice, such overestimations are common, whether they harm performance, and whether they can generally be prevented. Reinforcement Learning (DQN) Tutorial¶ Author:. Let us go back to the pseudocode for deep Q-learning:.
This one summarizes all of the RL tutorials, RL courses, and some of the important RL papers including sample code of RL algorithms. The quantiles for normalization can be either empirical or theoretical. Building a deep reinforcement learning library for DL4J:.
…(drums roll) … RL4J!. Reinforcement Learning (RL) Tutorial. Conversely, pseudocode is nothing but a more simple form of an algorithm which involves some part of natural language to enhance the understandability of the high-level programming constructs or for making it more human-friendly.
Download high-res image (499KB) Download :. Write an algorithm that takes a word as input and returns all. Algorithms - Lecture 1 5 Efficiency An algorithm should use a reasonable amount of computing resources:.
Recent DQN algorithm, which combines Q-learning with a deep neural network, suffers from substantial overestimations in some games in the Atari 2600 domain. Def retrieve ( n , s ):. The learning function, action function, etc.
Are you training the network using evolutionary algorithms?). DQN updates the Q-value function of a state for a specific action only. Pseudocode is a "text-based" detail (algorithmic) design tool.
However, both the problem to be solved and the recipe/algorithm. My 2 month summer internship at Skymind (the company behind the open source deeplearning library DL4J) comes to an end and this is a post to summarize what I have been working on:. Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning.
We then show that the idea behind the Double Q-learning algorithm, which was introduced in a tabular setting, can be generalized to work with large-scale function approximation. There are many RL tutorials, courses, papers in the internet. Train an agent to win a car racing game using dueling DQN;.
It takes the local and global variables. This time our main topic is Actor-Critic algorithms, which are the base behind almost every modern RL method from Proximal Policy Optimization to A3C. The DQN family (Double DQN, Dueling DQN, Rainbow) is a reasonable starting point for discrete action spaces, and the Actor-Critic family (DDPG, TD3, SAC) would be a starting point for continuous spaces.
The resulting algorithm is called Deep Q-Network (DQN). Consider a dictionary containing words. Right , s - n.
Val >= s :. Left , s ) else :. Deep Q-learning with Experience Replay;.
The main difference between algorithm and pseudocode is that an algorithm is a step by step procedure to solve a given problem while a pseudocode is a method of writing an algorithm. The idea behind Actor-Critics and how C and A3C improve them. Algorithm Using Flowchart and Pseudo Code Level 3 Pseudo.
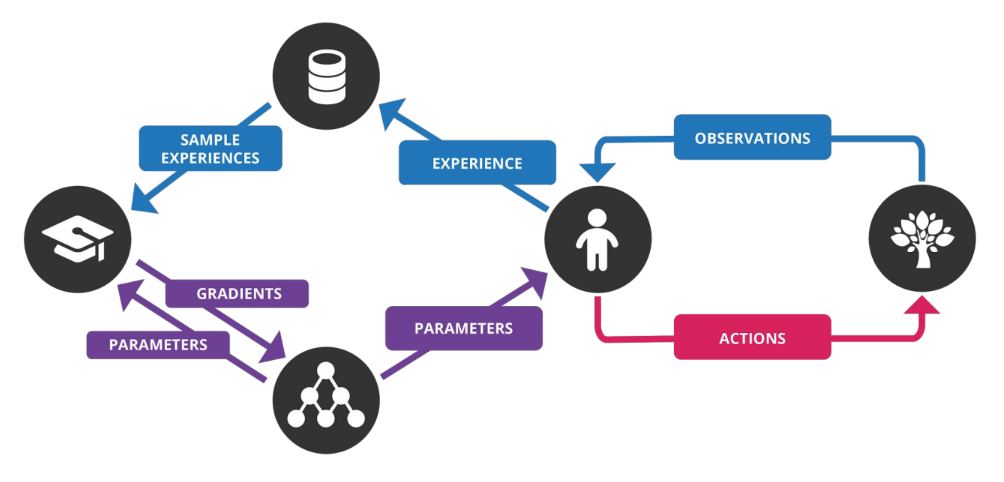
The algorithm decouples acting from learning:. Reinforcement Learning (RL) is the trending and most promising branch of artificial intelligence. DQN-based self-training Algorithm 1 shows pseudocode for DQN-based self-training, which consists of three main steps.
In this algorithm, on the basis of how the gradient has been changing for all the previous iterations we try to change the learning rate. It can be proven that given sufficient training under any -soft policy, the algorithm converges with probability 1 to a close approximation of the action-value function for an arbitrary target policy.Q-Learning learns the optimal policy even when actions are selected according to a more exploratory or even. We can summarize the previous explanations with this pseudocode for the basic DQN algorithm that will guide our implementation of the algorithm:.
#create two networks and synchronize current_model, target_model = DQN(num_states, num_actions), DQN(num_states, num_actions). This article is the third part of a series of blog post about Deep Reinforcement Learning. For a value s, , we use the following algorithm (pseudo code):.
Second, it makes decisions about instance acceptance or rejection. The Deep Q-Network (DQN) algorithm, as introduced by DeepMind in a NIPS 13 workshop paper, and later published in Nature 15 can be credited with revolutionizing reinforcement learning. Use CNN to estimate state value function;.
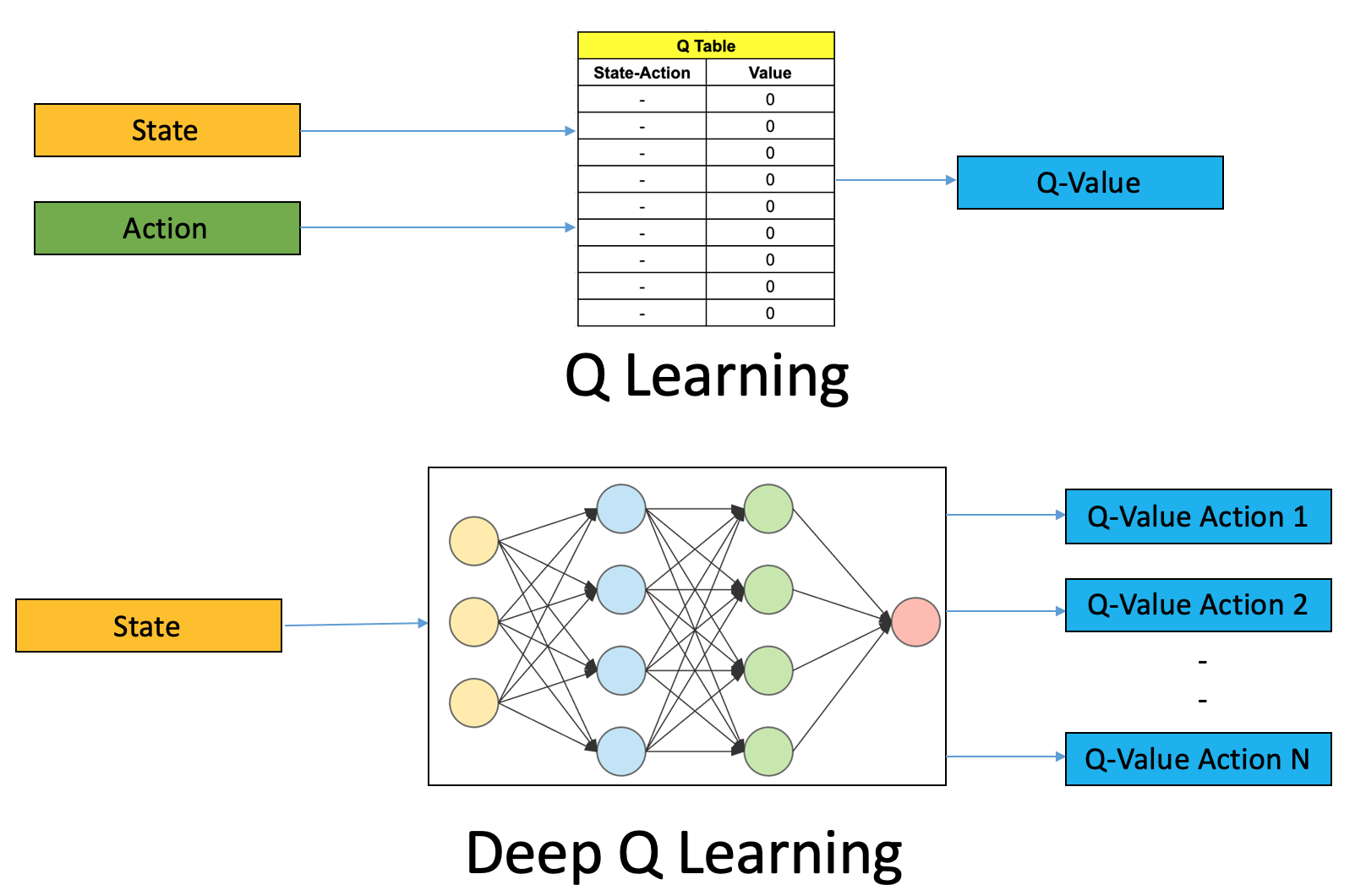
But as we’ll see, producing and updating a Q-table can become ineffective in big state space environments. That they be expressed in Java or other widely used programming languages. Learn an approximate.
Return n if n. One can explicitly use different exploration policies in each actor-learner to maximize this diversity. Return retrieve ( n.
From the pseudo code above you may notice two action selection are performed, which always follows the current policy. A computer program generally tries to solve a well-defined problem using a well-defined algorithm. It uses a deep network to represent the value function, which is based onQ-Learning, to provide target values for deep networks, and to constantly update the network until convergence.
Hands-On Reinforcement learning with Python will help you master not only the basic reinforcement learning algorithms but also the advanced deep reinforcement learning algorithms. 2.3 Deep Q Network (DQN). Return retrieve ( n.
Therefore, SARSA is an on-policy algorithm. Why Should I Write Pseudocode?. PQN is the non-central trimmed mean of perfect match intensities with quantile normalization.
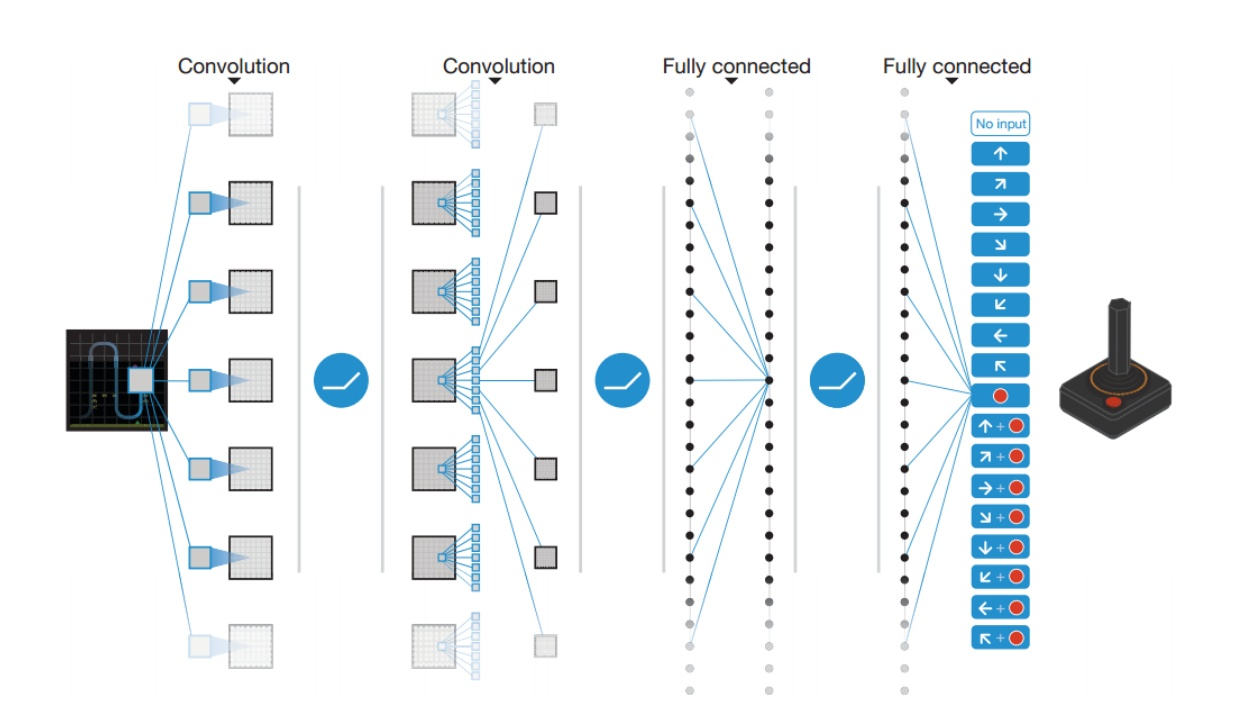
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. I encourage you to try the DQN algorithm on at least 1 environment other than CartPole to practice and understand how you can tune the model to get the best results. Reinforcement Learning Algorithms Part1:DQN Nature DQN.
To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task:. The Basic DQN Algorithm. Here’s a pseudocode grad_component = previous_grad_component + (gradient * gradient) rate_change = square_root(grad_component) + epsilon adapted_learning_rate = learning_rate * rate_change.
Are all otherwise the same. Q-learning with continuous actions Option 3:. Once an instance is.
A DQN agent is a value-based reinforcement learning agent that trains a critic to estimate the return or future rewards. The following is the algorithm to fit Q with the sampled rewards. Pseudocode is an artificial and informal language that helps programmers develop algorithms.
This algorithm was later modified clarification needed in 15 and combined with deep learning, as in the DQN algorithm, resulting in Double DQN, which outperforms the original DQN algorithm. Pseudocode for the actors and learners is shown in Algorithms 1 and 2. If it returns False, training is aborted.
All statements showing "dependency" are to be indented. The tasks considered are those in which an agent interacts with an environment, in this case the Atari emulator, in a sequence of actions, observations and rewards. The popular Q-learning algorithm is known to overestimate action values under certain conditions.
DQN pseudocode Algorithm 1 DQN initialize for Q ,set ¯ – for each step do if new episode, reset to s 0 observe current state s t take -greedy action a t based on Q ps t, ¨q ⇡pa t |s t q“ # 1 ´ |A|´1 |A| a t “ argmax a Q ps t,aq 1 |A| otherwise get reward r t and observe next state s t`1 add ps t,a t,r t,s t`1 q to replay buffer D. So when I read about the incredible algorithms DeepMind was coming up with (like AlphaGo and AlphaStar), I was hooked. Pseudocode often uses structural conventions of a normal programming language, but is intended for human reading rather than machine reading.It typically omits details that are essential for machine understanding of the algorithm, such as variable declarations and language-specific code.
This is a major consideration for selecting a reinforcement learning algorithm. Implementing Double Q-Learning with PyTorch. I suggest you take a look at 'Sutton and Barto (Second Edition)' for a detailed description of the wide variety of algorithms.
In order to implement this, all we need to change from our DQN algorithm is to modify the calculation of our target. DQN is a variant of Q-learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards.
If n is leaf_node :. Process 3 in the inner loop of process 2, which is in. In particular, we first show that the recent DQN algorithm, which combines Q.
The agent has to decide between two actions - moving the cart left or right - so that the pole attached to it stays upright. The crucial difference between algorithm and pseudocode is that an algorithm is a sequence of steps which is utilized in order to solve a computational problem. They must derive efficient.
It’s time for some Reinforcement Learning. RL algorithms don't learn randomly. Stack Overflow for Teams is a private, secure spot for you and your coworkers to find and share information.
The rules of Pseudocode are reasonably straightforward. Updated network parameters are periodically communicated to the actors from the learner.
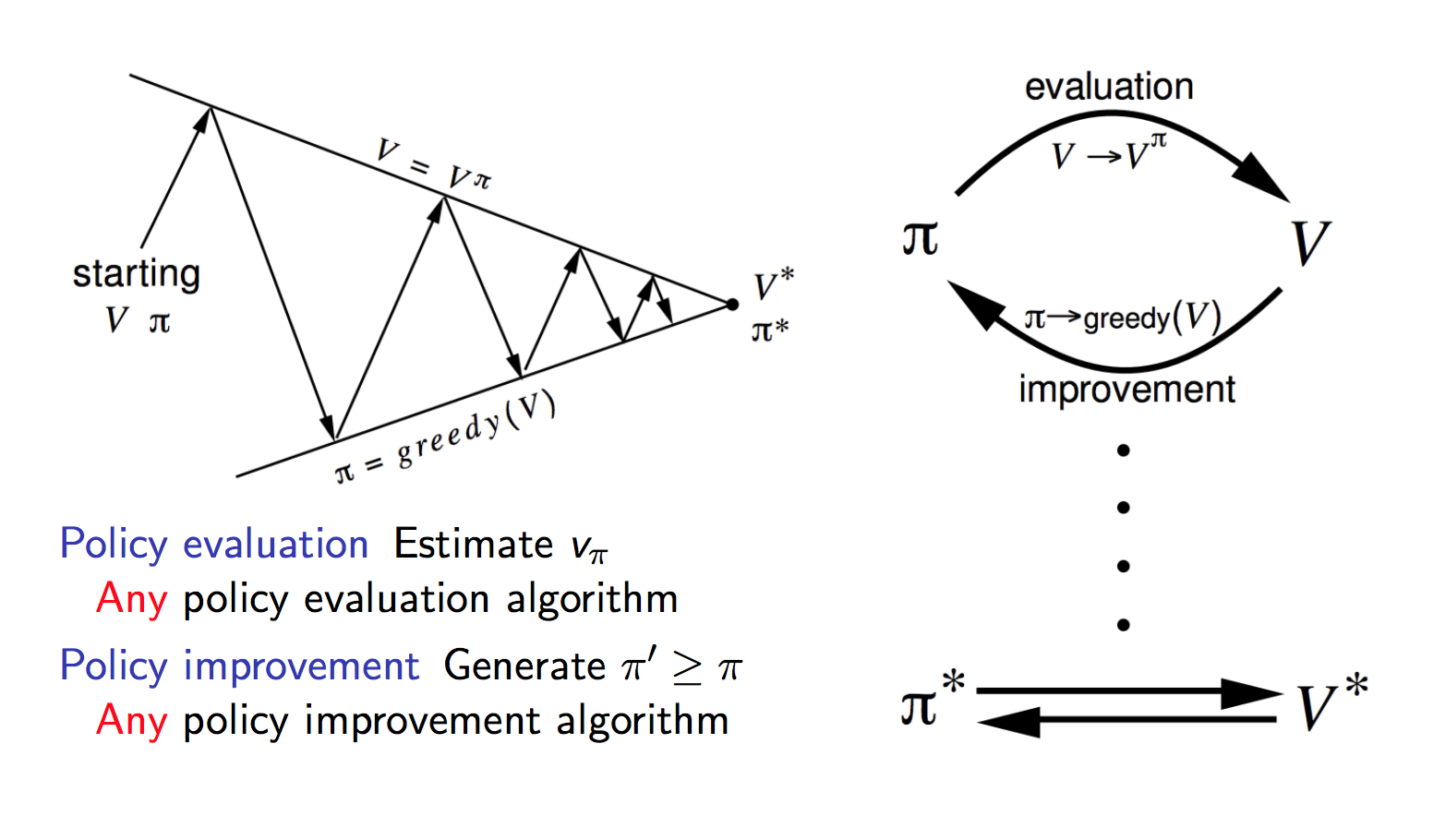
Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
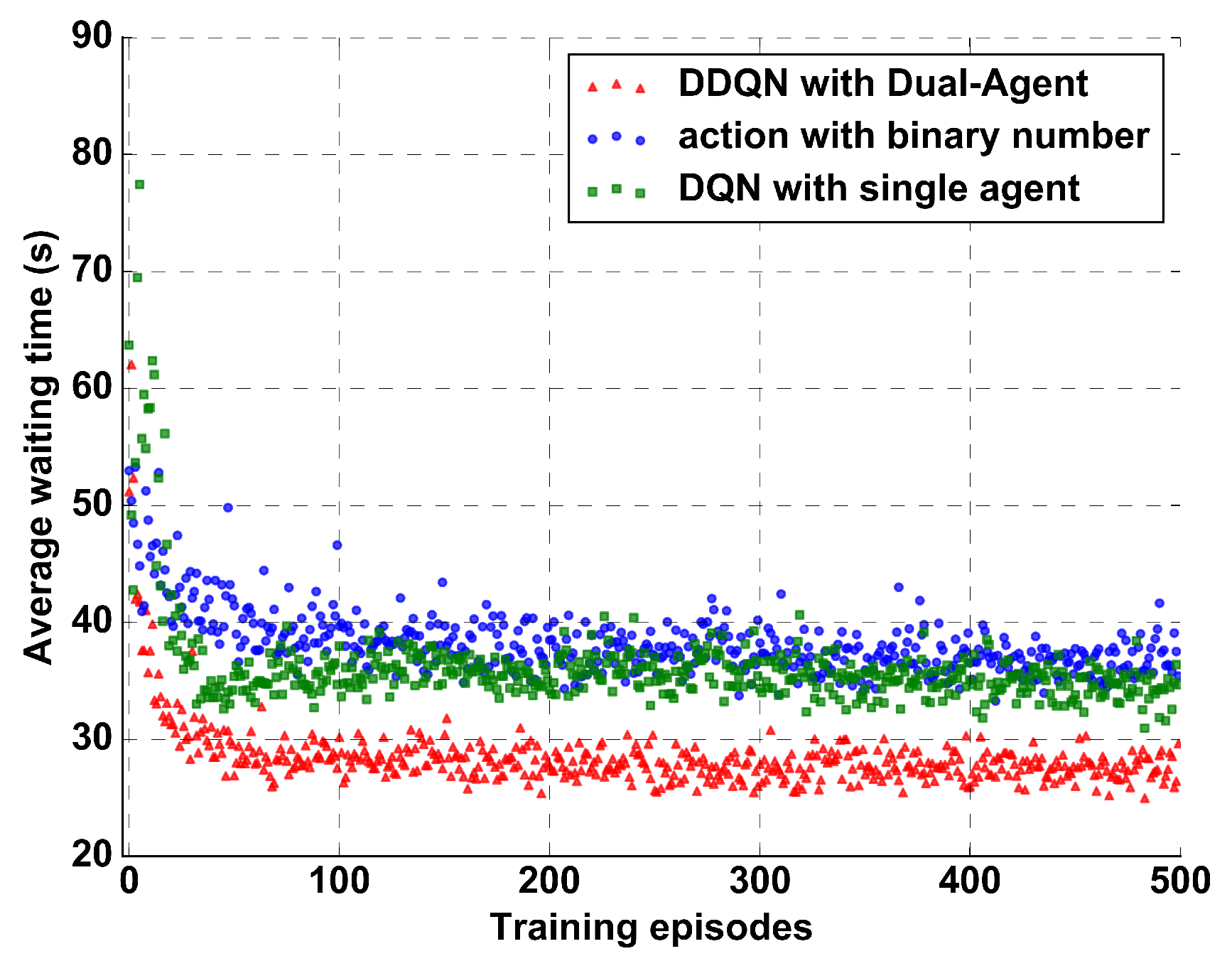
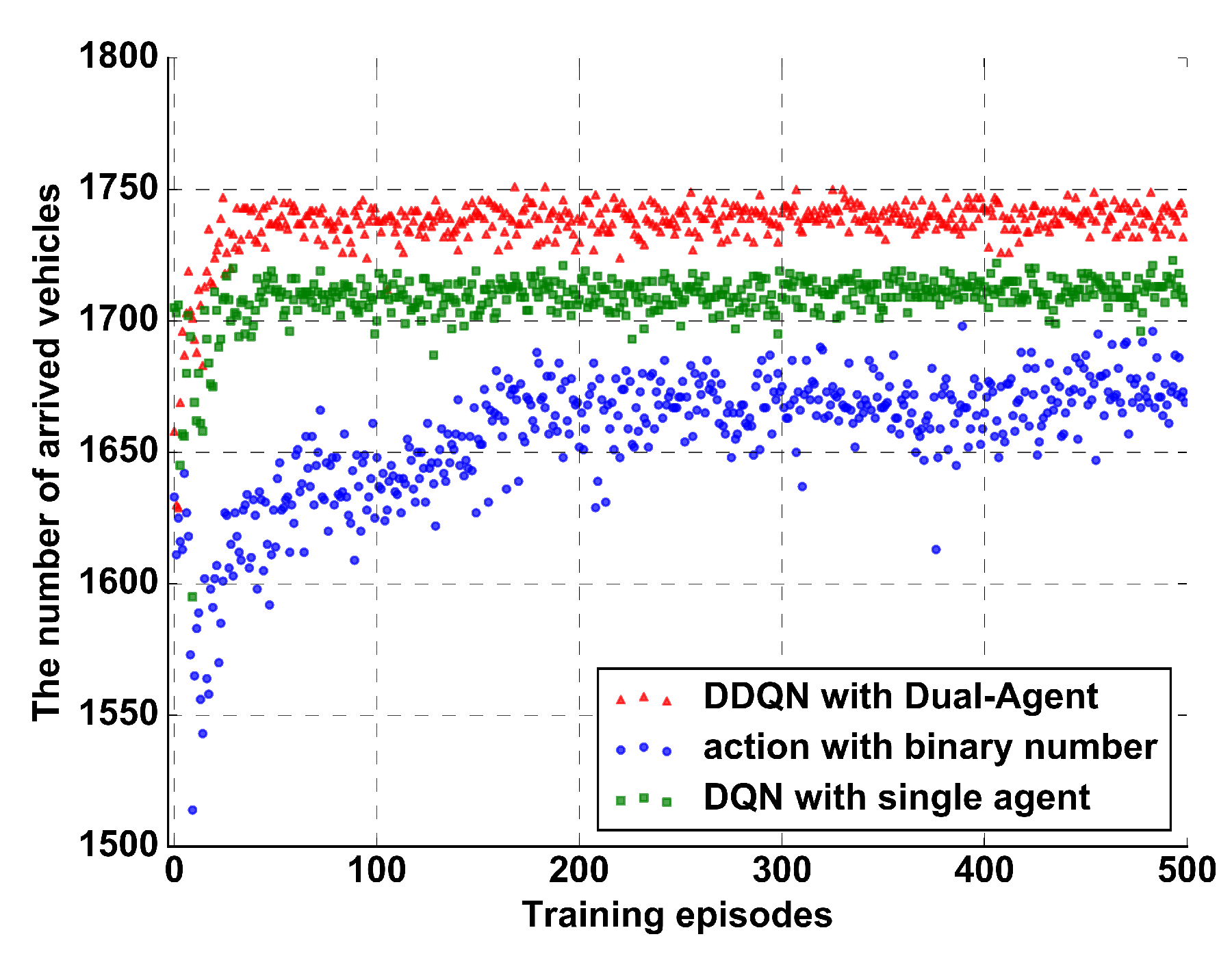
Applied Sciences Free Full Text Double Deep Q Network With A Dual Agent For Traffic Signal Control Html

Policy Gradient Algorithms

Policy Gradient Algorithms
Arxiv Org Pdf 1701

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
Deep Q Learning An Introduction To Deep Reinforcement Learning

Part 7 Deep Q Learning Data Machinist
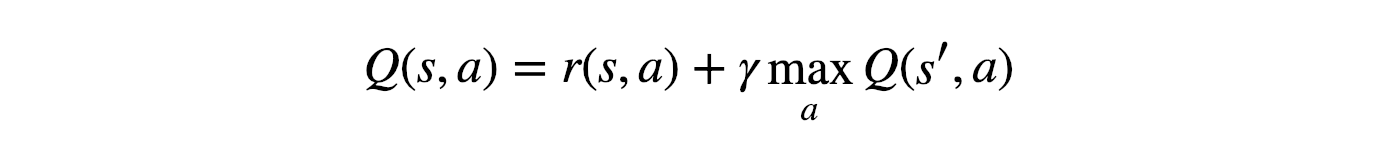
Deep Q Learning An Introduction To Deep Reinforcement Learning

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Rl Reinforcement Learning Algorithms Quick Overview By Jonathan Hui Medium
Deep Reinforcement Learning

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
2

What Is Phi In Deep Q Learning Algorithm Stack Overflow

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium

Deep Q Network Dqn Ii Experience Replay And Target Networks By Jordi Torres Ai Aug Towards Data Science

Multi Agent Reinforcement Learning In Beer Distribution Game Laptrinhx
Symmetry Free Full Text Supervised Reinforcement Learning Via Value Function Html

Task Scheduling Based On Deep Reinforcement Learning In A Cloud Manufacturing Environment Dong Concurrency And Computation Practice And Experience Wiley Online Library
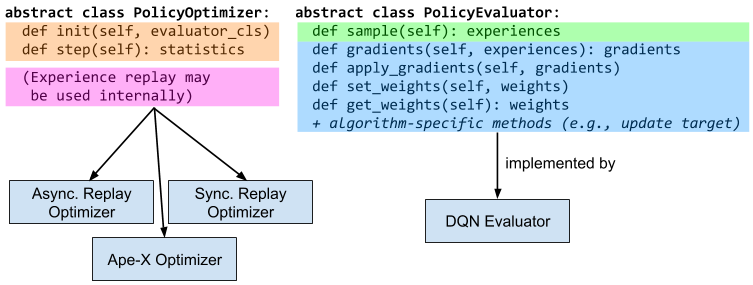
Distributed Policy Optimizers For Scalable And Reproducible Deep Rl Rise Lab

Goai 1 Asynchronous Methods For Deep Reinforcement Learning By Darrenyaoyao Medium

Asynchronous Methods For Deep Reinforcement Learning The Morning Paper
Applied Sciences Free Full Text Double Deep Q Network With A Dual Agent For Traffic Signal Control Html

Reinforcement Learning Dqn Related Knowledge And Code Implementation Programmer Sought

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink

Deep Reinforcement One Shot Learning For Artificially Intelligent Classification In Expert Aided Systems Sciencedirect

The Pseudo Code Of The Cbmpi Algorithm Download Scientific Diagram
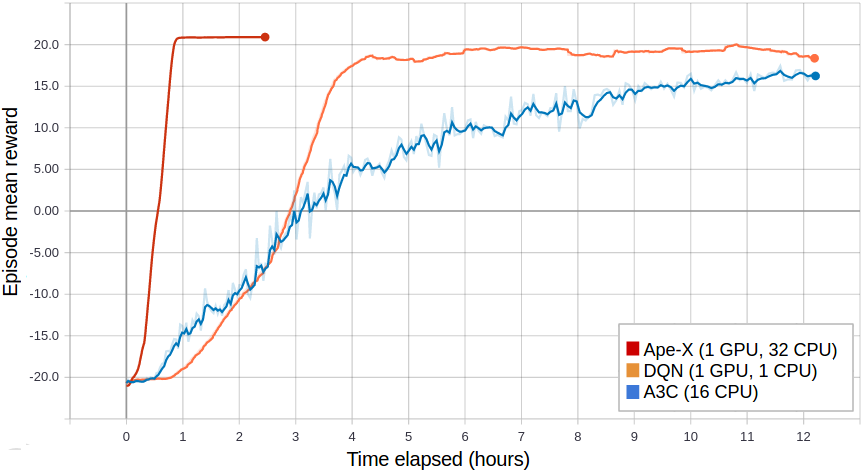
Distributed Policy Optimizers For Scalable And Reproducible Deep Rl Rise Lab
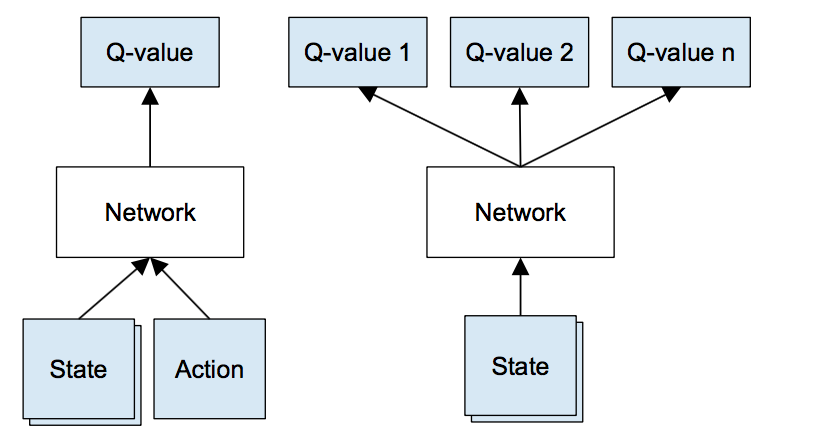
Reinforcement Learning And Dqn Learning To Play From Pixels Ruben Fiszel S Website

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink

Deep Q Learning An Introduction To Deep Reinforcement Learning

Deep Q Learning Part2 Double Deep Q Network Double Dqn By Amber Medium
Deep Q Learning Series Dqn Liao Yong Technology Space

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink

Multi Agent Reinforcement Learning In Beer Distribution Game Laptrinhx
Deep Q Learning An Introduction To Deep Reinforcement Learning

Deep Reinforcement Learning With Hidden Layers On Future States Springerlink

Task Scheduling Based On Deep Reinforcement Learning In A Cloud Manufacturing Environment Dong Concurrency And Computation Practice And Experience Wiley Online Library

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink
Http Proceedings Mlr Press V48 Mniha16 Pdf

Pdf A Comparative Performance Study Of Reinforcement Learning Algorithms For A Continuous Space Problem

Reinforcement Learning Algorithms
Reinforcement Learning And Dqn Learning To Play From Pixels Ruben Fiszel S Website

Relationships Between Dp Rl Prioritized Sweeping Prioritized Experience Replay Etc Czxttkl

Q Learning Wikipedia
Arxiv Org Pdf 1905

Policy Gradient Algorithms
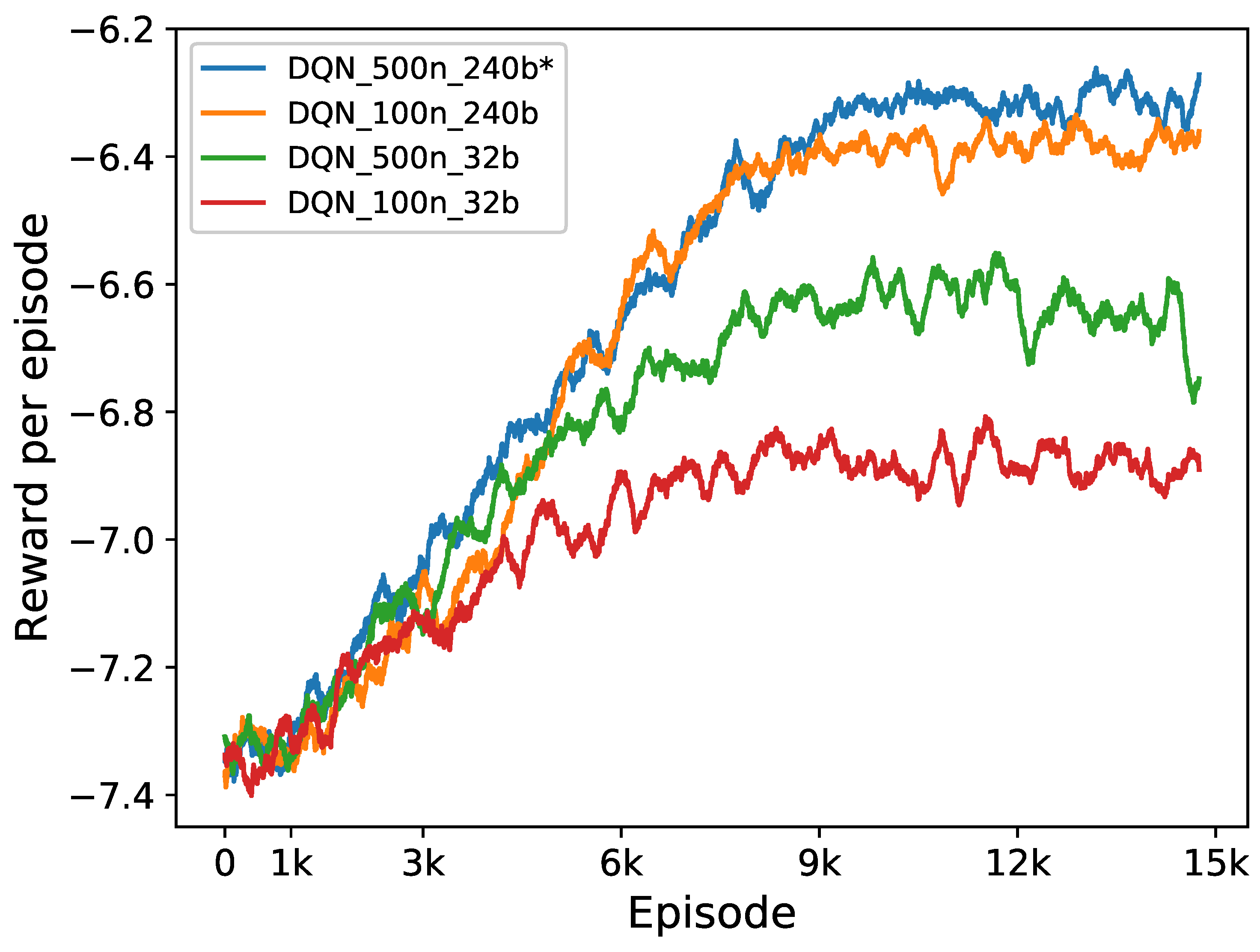
Energies Free Full Text Real Time Energy Management Of A Microgrid Using Deep Reinforcement Learning Html
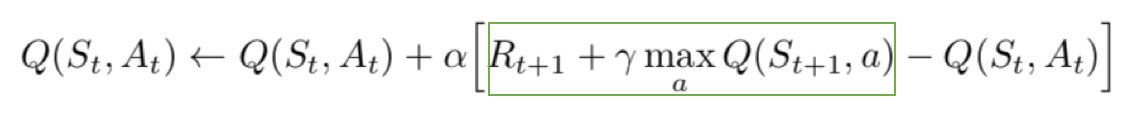
Deep Q Learning An Introduction To Deep Reinforcement Learning

Double Q Reinforcement Learning In Tensorflow 2 Adventures In Machine Learning

Q Learning Wikipedia

Diving Deeper Into Reinforcement Learning With Q Learning

Q Tbn 3aand9gcsbd8qt8pdmctuh7zspti7o1jeik2gbar4afq Usqp Cau

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Can Someone Please Explain The Target Update For Deep Q Learning Cross Validated

Policy Gradient Algorithms

Noisy Dqn Programmer Sought

Rl Reinforcement Learning Algorithms Quick Overview Mc Ai
Q Tbn 3aand9gcru6fh2v60x73gspddyw74dbvi34wcmsqwc5jz44k7ymhq116lg Usqp Cau

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Deep Q Learning With Tensorflow 2 By Aniket Gupta Medium

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Reinforcement Learning Algorithms
Deep Q Learning An Introduction To Deep Reinforcement Learning

Deep Sarsa Deep Q Learning Dqn
Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Deep Reinforcement Learning In Strategic Board Game Environments Springerlink

Lei Mao S Log Book Making Reinforcement Learning Agent Library

Diving Deeper Into Reinforcement Learning With Q Learning

Pytorch Reinforcement Learning Teaching Ai How To Play Flappy Bird Toptal
Http Proceedings Mlr Press V48 Mniha16 Pdf

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Distributed Policy Optimizers For Scalable And Reproducible Deep Rl Rise Lab

Yad Neat Deep Reinforcement Learning An Overview About Pages Still Missing Topics But Good Stuff W Pointers T Co Aghih35zxi T Co Wtnrborfen
Reinforcement Learning And Dqn Learning To Play From Pixels Ruben Fiszel S Website

Deep Sarsa Deep Q Learning Dqn

Deep Q Learning Series Dqn Liao Yong Technology Space
3

Policy Gradient Algorithms

Reinforcement Learning 6 Temporal Difference Learning

Asynchronous Deep Reinforcement Learning From Pixels Dmitry Bobrenko S Blog
Arxiv Org Pdf 1905

Task Scheduling Based On Deep Reinforcement Learning In A Cloud Manufacturing Environment Dong Concurrency And Computation Practice And Experience Wiley Online Library

Rl Reinforcement Learning Algorithms Quick Overview Mc Ai

Reinforcement Learning Dqn Tutorial Pytorch Tutorials 1 6 0 Documentation
Arxiv Org Pdf 1708

Lei Mao S Log Book Making Reinforcement Learning Agent Library
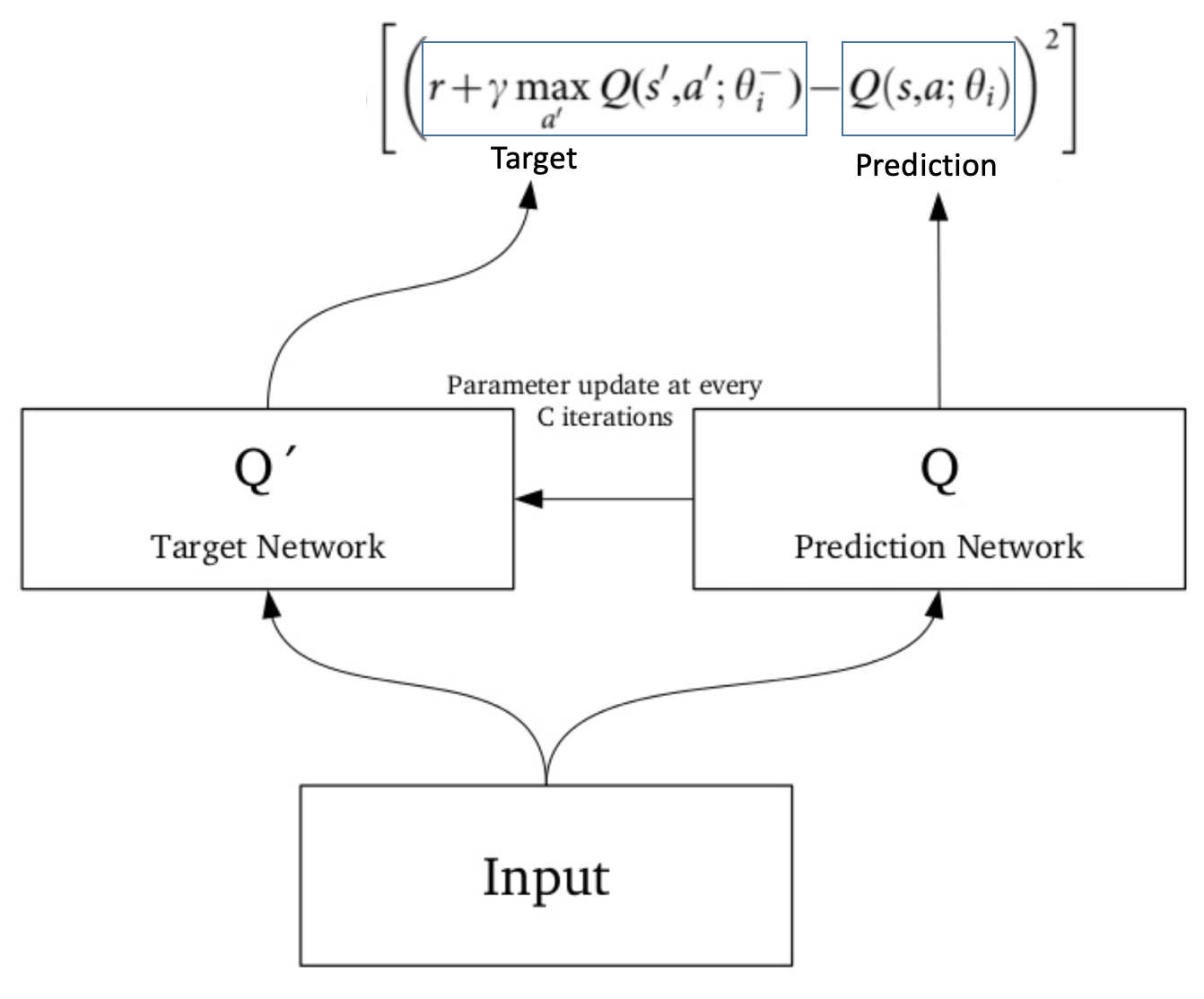
Deep Q Learning An Introduction To Deep Reinforcement Learning

Deep Q Learning An Introduction To Deep Reinforcement Learning

Policy Gradient Algorithms

Deep Deterministic Policy Gradient Spinning Up Documentation
Deep Q Learning Mc Ai

Distributional Bellman And The C51 Algorithm Felix Yu
ourses Berkeley Edu Files Download Download Frd 1

Asynchronous Reinforcement Learning Algorithms For Solving Discrete Space Path Planning Problems Springerlink



