Double Dqn Pseudocode
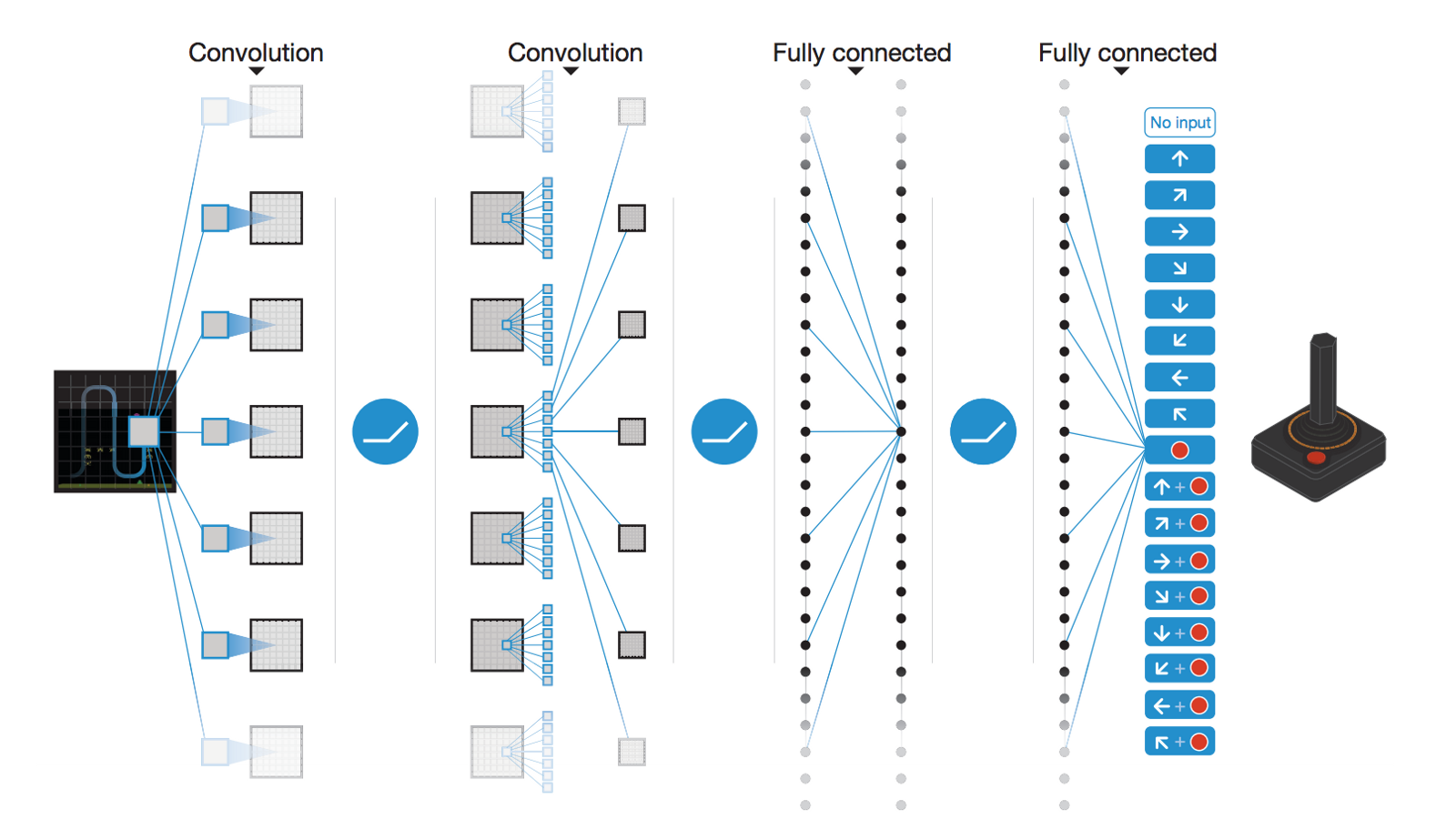
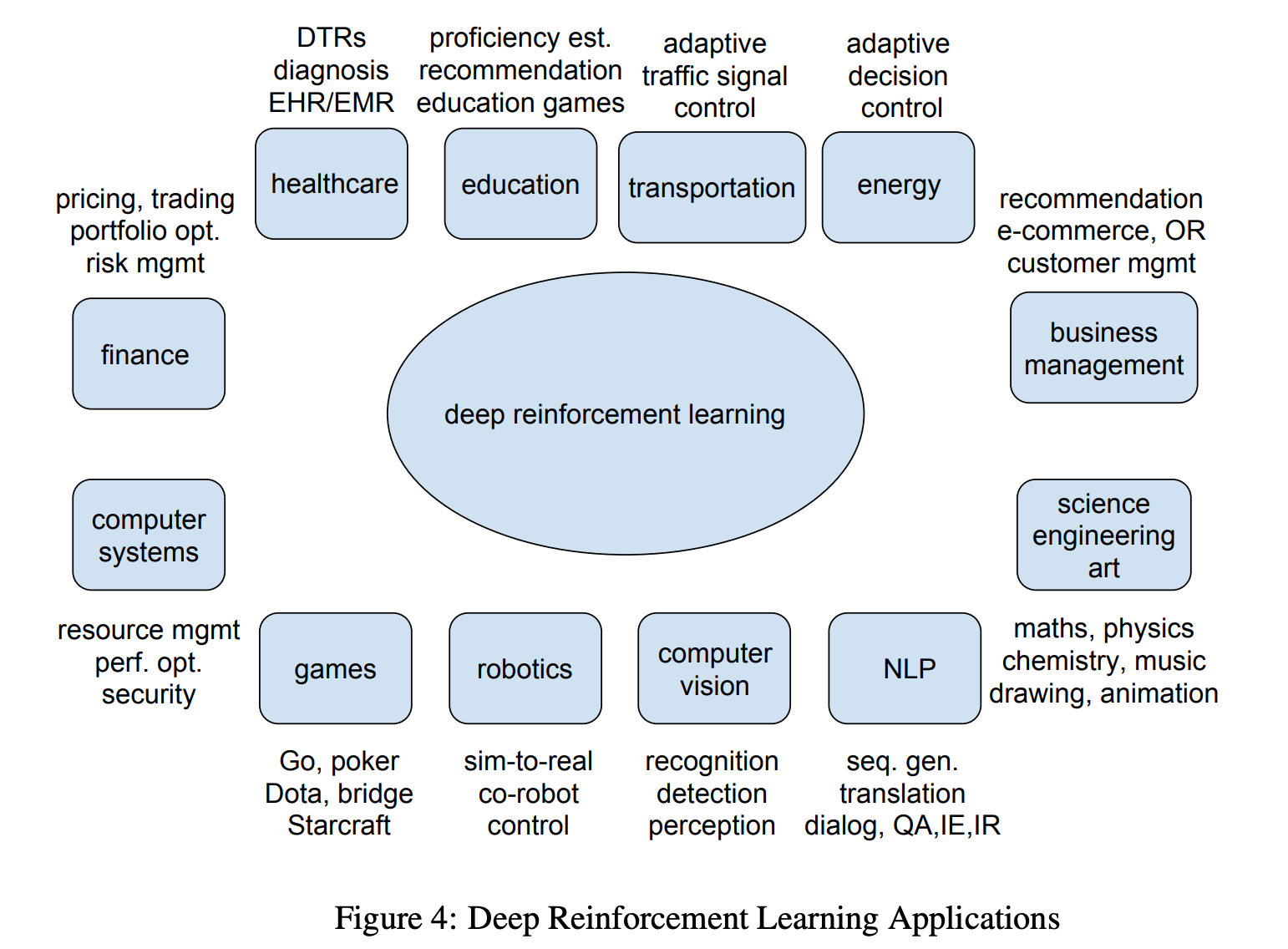
Deep Reinforcement Learning

Pdf A Comparative Performance Study Of Reinforcement Learning Algorithms For A Continuous Space Problem

Is A Comparison With Nec2dqn Double Dqn And N Step Dqn N 10 Download Scientific Diagram
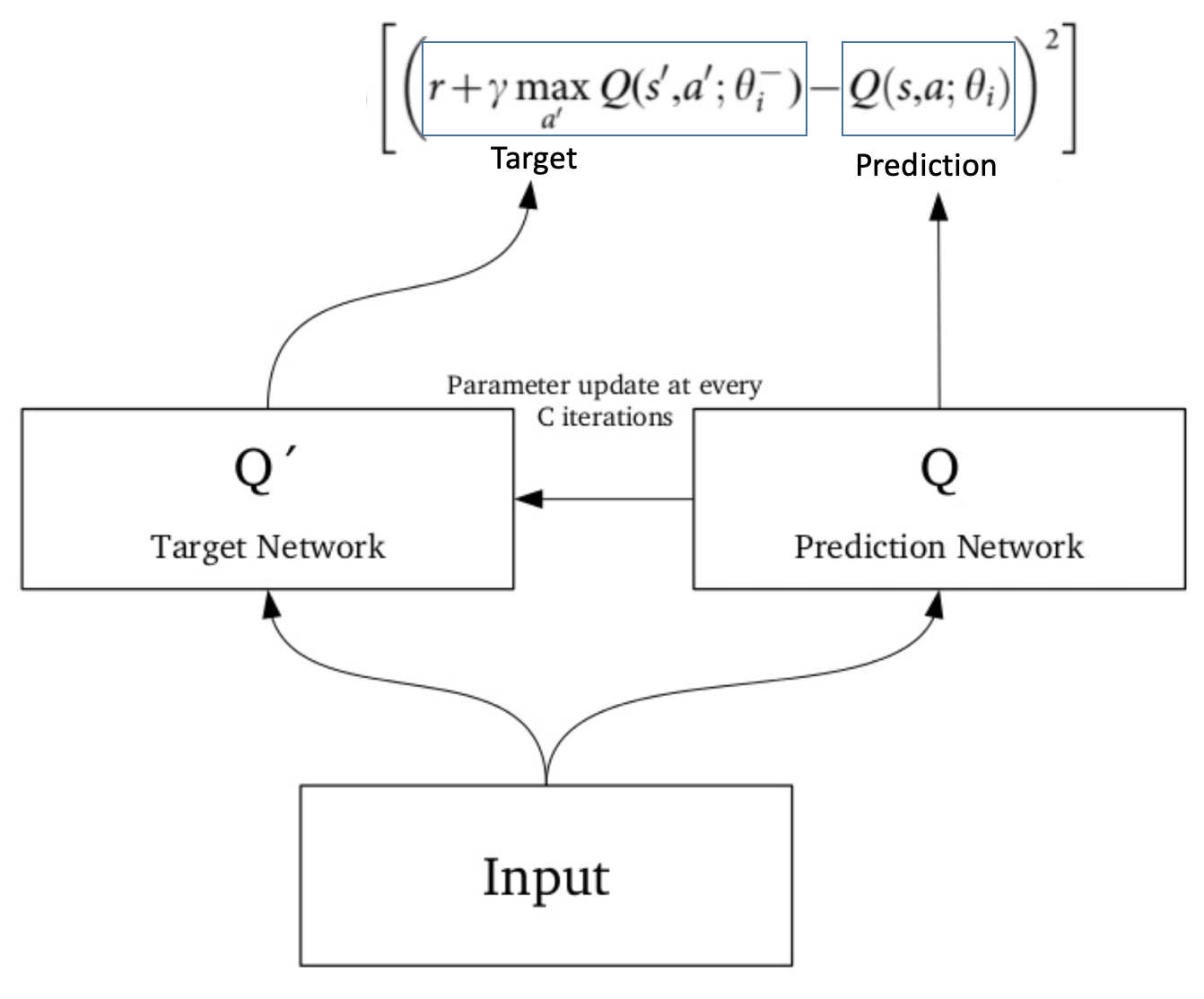
Deep Q Learning An Introduction To Deep Reinforcement Learning

Td3 Learning To Run With Ai Learn To Build One Of The Most Powerful By Donal Byrne Towards Data Science

Deep Q Learning An Introduction To Deep Reinforcement Learning
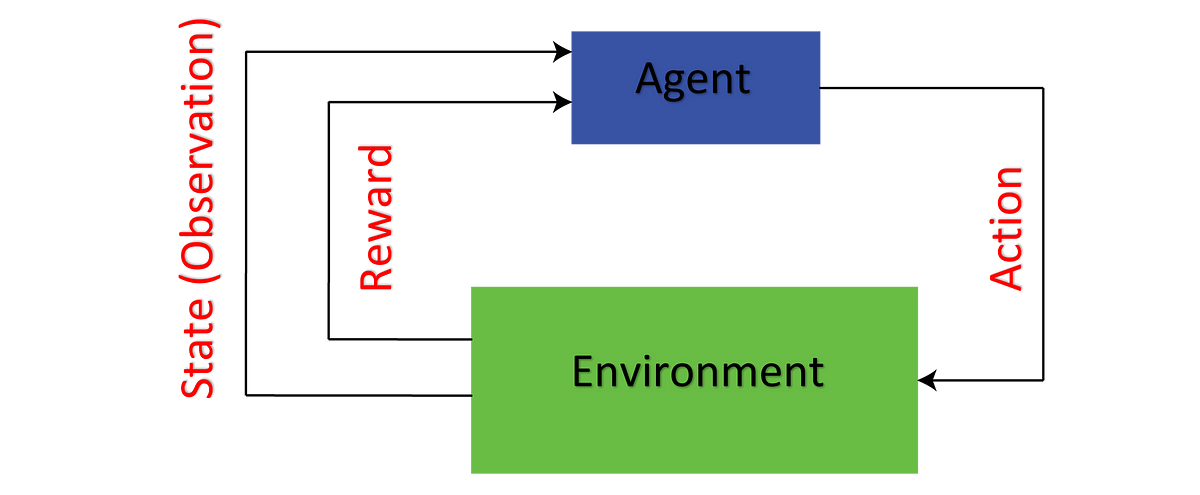
As stated above, reinforcement learning comprises of a few fundamental entities or concepts.
Double dqn pseudocode. Much of the research refers to fixed-Q targets as Double DQN. In this case, the colon appears to be a range operator. Moreover, the dueling architecture enables our RL agent to outperform the state-of-the-art Double DQN method of van Hasselt et al.
However, the max operation creates a positive bias towards the Q estimations. Process 3 in the inner loop of process 2, which is in. Inspired by Double Q-Learning, Double DQN.
We then show that this algorithm not only yields more. In the appendix, the authors provide the pseudocode for Double DQN. But, you can find it in the Dueling DQN paper, which is a subsequent paper where Van Hasselt is a coauthor.
Usually the meaning is either obvious from context or the author provides some kind of key to the symbols they use. Dqn.test(env, nb_episodes=5, visualize=True) This will be the output of our model:. For an experimental study of the contribution of each mechanism and the corresponding Rainbow DQN network, using in addition distributional learning, see Section 4.7.1).
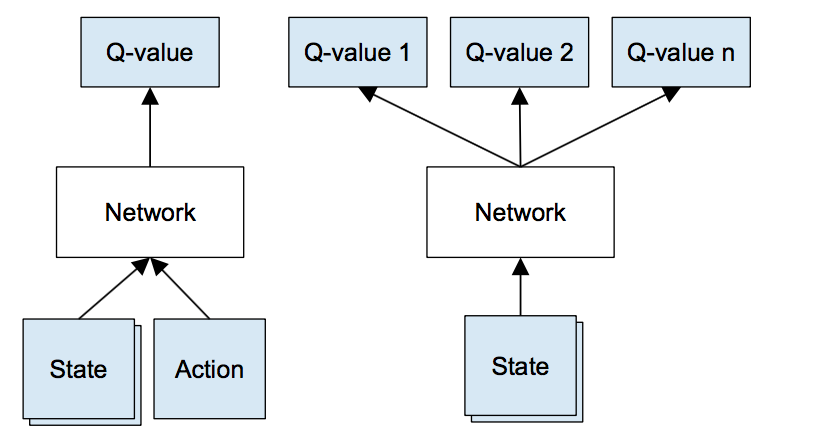
A DQN agent is a value-based reinforcement learning agent that trains a critic to estimate the return or future rewards. You'll be assessed on your understanding of how to use and write pseudocode. We then show that the idea behind the Double Q-learning algorithm, which was introduced in a tabular setting, can be generalized to work with large.
The Double Q-learning algorithm is an adaption of the DQN algorithm that reduces the observed overestimation, and also leads to much better performance on several Atari games. Pseudo Code Practice Problems:. In particular, we first show that the recent DQN algorithm, which combines Q-learning with a deep neural network, suffers from substantial overestimations in some games in the Atari 2600 domain.
Dqn.fit(env, nb_steps=5000, visualize=True, verbose=2) Test our reinforcement learning model:. The pseudocode of our 3DQN with prioritized experience replay is shown in Algorithm 1. This quiz/worksheet combo will help you test your understanding of pseudocode.
Its goal is to train a mature adaptive traffic light, which can change its phases’ duration based on different traffic scenarios. ZPseudocode programs are not executed on computers. Reinforcement Learning (RL) is the trending and most promising branch of artificial intelligence.
About This Quiz & Worksheet. A complete pseudocode algorithm for REINFROCE with baseline is given in the box (use Monte Carlo method for learning the policy parameter and state-value weights). “Double Q-learning” (Hasselt, 10) The original Double Q-learning algorithm uses two independent estimates Q^{A}and Q^{B}.
Pseudo code Pseudo code can be broken down into five components. Process 1 and process 3 run at the same speed, process 2 is slow •Fitted Q-iteration:. Deep Reinforcement Learning with Double Q-learning.
It is convenient and user friendly although it is not an actual computer programming language. Conversely, we use Q^{B} to determine the maximizing action, but use it to update Q^{A}. The agent first chooses actions randomly till the number of steps is over.
Can train both feedforward and recurrent agents. Human-level Control through Deep Reinforcement Learning. Although DQN achieved huge success in higher dimensional problem, such as the Atari game, the action space is still discrete.
DQN is a variant of Q-learning. The voltage (V) between the poles of a conductor is equal to the product of the current (I) passing through the conductor and the resistance (R) present on the conductor.It’s demonstrated by the V = I * R formula. Write a program to add two numbers in C# crayon-….
Use Q1 and Q2 to indicate. This improved stability directly translates to ability to learn much complicated tasks. X/y is the integer quotent of x divided by y.
Pseudocode and C Language Review Pseudocode zPseudocode is an artificial and informal language that helps you develop algorithms. Pseudocode is another useful method for designing software and this is a program outline in text form that can be entered directly into the source code editor as a set of general statements that describe each major block, which would be defined as functions and procedures in a high-level language and subroutines and macros in a low-level language. The policy and value functions share all parameters apart from those in the final output layers.
Q-learning is a model-free reinforcement learning algorithm to learn quality of actions telling an agent what action to take under what circumstances. The deep Q-network (DQN) algorithm is a model-free, online, off-policy reinforcement learning method. We show that the idea behind the Double Q-learning algo-rithm (van Hasselt, 10), which was first proposed in a tab-ular setting, can be generalized to work with arbitrary func-tion approximation, including deep neural networks.
Several improvements have been proposed since the. We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. Pseudocode Examples C# Console Code:.
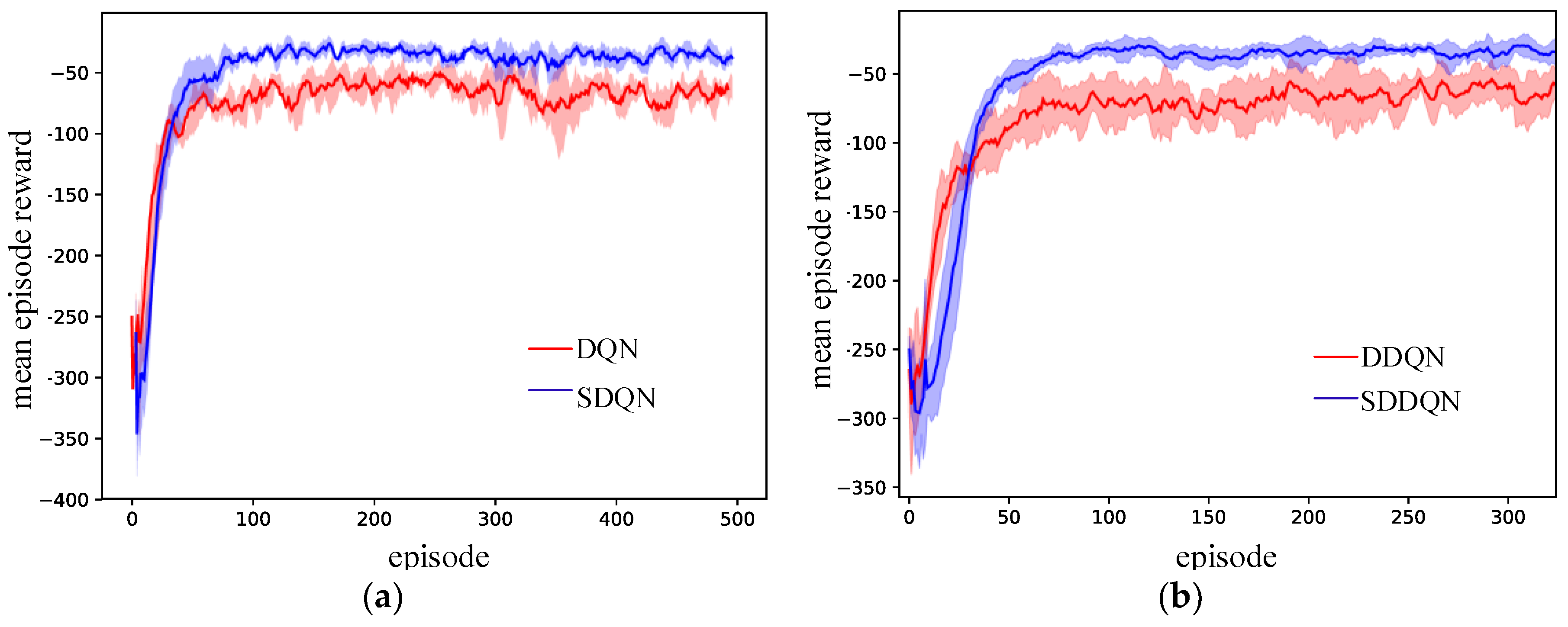
Our network architecture was inspired by the model of Mnih et al. Download high-res image (5KB) Download :. The Deep Reinforcement Learning with Double Q-learning 1 paper reports that although Double DQN (DDQN) does not always improve performance, it substantially benefits the stability of learning.
Use Q1 and Q2 to indicate. Add Two Numbers Program Pseudocode Algorithm crayon-5f81f566af36f/ You May Also Like:. I have read some articles, but still can not figure out the difference between the Dueling DQN and Double DQN?.
Since pseudocode is an informal description of code, any particular piece of pseudocode means whatever the author intended it to mean. However, Mnih originally referred. Remember that Q-values correspond to how good it is to be at that state and taking an action at that state Q(s,a).
This book starts by presenting the basics of reinforcement learning using highly intuitive and easy-to-understand examples and applications, and then introduces the cutting-edge research advances that make reinforcement learning capable of out-performing most state-of-art systems, and even humans in a number of applications. It does not require a model (hence the connotation "model-free") of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. Implementation Dueling DQN (aka DDQN) Theory.
This is in reference to Double Q-Learning, by vanHasselt10. As code, this gives us the following:. In the appendix, the authors provide the pseudocode for Double DQN.
The entire Double DQN training loop is given in pseudocode in Algorithm 1 below. Stack Overflow for Teams is a private, secure spot for you and your coworkers to find and share information. Therefore, Double DQN helps us reduce the overestimation of q values and, as a consequence, helps us train faster and have more stable learning.
Double Q-Learning (15 points) Please go to theProblem 2 Appendix(at the end of the document) to read the motivations and tutorials needed for this problem. When testing DDQN on 49 Atari games, it achieved about twice the average score of DQN with the same hyperparameters. Pseudocode is not a formal language.
As pseudocode, the algorithm looks like this:. It does not require a model (hence the connotation "model-free") of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations. Reinforcement-learning q-learning dqn deep-network.
For more information on Q-learning, see Q-Learning Agents. Please provide pseudocode for the Double Q-learning algorithm. Hands-On Reinforcement learning with Python will help you master not only the basic reinforcement learning algorithms but also the advanced deep reinforcement learning algorithms.
Q-Learning is an Off-Policy algorithm for Temporal Difference learning. Double DQN is proposed in H. Double Q-Learning in Practice:.
In Q-learning, we use the following formula for the target value for Q. Double DQN Singificantly improves to Deep Q-Network (DQN) Q-Learning with Q estimated with artificial neural networks Implemented in almost all DQN papers afterwards Results on Atari 2600 games. ZPseudocode is similar to everyday English;.
With double Q-learning (and other tricks) Q-learning with continuous actions •Continuous control with deep reinforcement learning, Lillicrap et al. Dueling Double DQN, Prioritized Experience Replay, and fixed Q-targets. In Mnih15, the Q-Learning algorithm was extended to deep neural networks and DQN was born!.
In C++, you write x. It can be proven that given sufficient training under any -soft policy, the algorithm converges with probability 1 to a close approximation of the action-value function for an arbitrary target policy.Q-Learning learns the optimal policy even when actions are selected according to a more exploratory or even. Asked May 31 '19 at 17:46.
With a 0.5 probability, we use estimate Q^{A} to determine the maximizing action, but use it to update Q^{B}. Maintains a policy (the actor) and a value function (the critic) The policy and value functions are updated after steps or when a terminal state is reached. OpenAI gym provides several environments fusing DQN on Atari games.
(15) in 46 out of 57 Atari games. What exactly is the difference between them?. Double Q-Learning implementation with Deep Neural Network is called Double Deep Q Network (Double DQN).
Mod is the integer remainder of the integer division of x by y. Double DQN (van Hasselt et al., 16a). We use the double DQN and dueling DQN to reduce.
Double Q-Learning (15 points) Please go to theProblem 2 Appendix(at the end of the document) to read the motivations and tutorials needed for this problem. However, many tasks of interest, especially physical control tasks, the action space is continuous. Congratulations on building your very first deep Q-learning model.
Train an agent to win a car racing game using dueling DQN;. The reason the Q-learning can sometimes learn unrealistically high actions values is as follows:. So we can decompose Q(s,a) as the sum of:.
Declare your arrays however you want, as long as it's obvious what you mean. Proximal Policy Optimization (PPO) with Sonic the Hedgehog 2 and 3. Double duelling DQN with prioritized replay was the state-of-the-art method for value-based deep RL (see Hessel et al.
Asynchronous Advantage Actor-Critic (A3C)¶ An on-policy asynchronous RL algorithm. Trivia quiz which has been attempted times by avid quiz takers. Please provide pseudocode for the Double Q-learning algorithm.
Also, Does Dueling DQN need to be built on. Div is the integer division function. If you discretize the action space too finely, you wind up having an action space that is too large.
Actor-Critic Methods Although the REINFORCE-with-baseline method learns both a policy and a state-value function, we do not consider it to be an actor-critic method because its state. Deep Q-Network (DQN) to learn the game 48 does not improve Hot Network Questions If the second hand goes backwards, starting from 12:00, how long does it take to meet with the minute hand?. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards.
Introduction to reinforcement learning. This interaction can be seen in the diagram below:. Listed below is a brief explanation of Pseudo code as well as a list of examples and solutions.
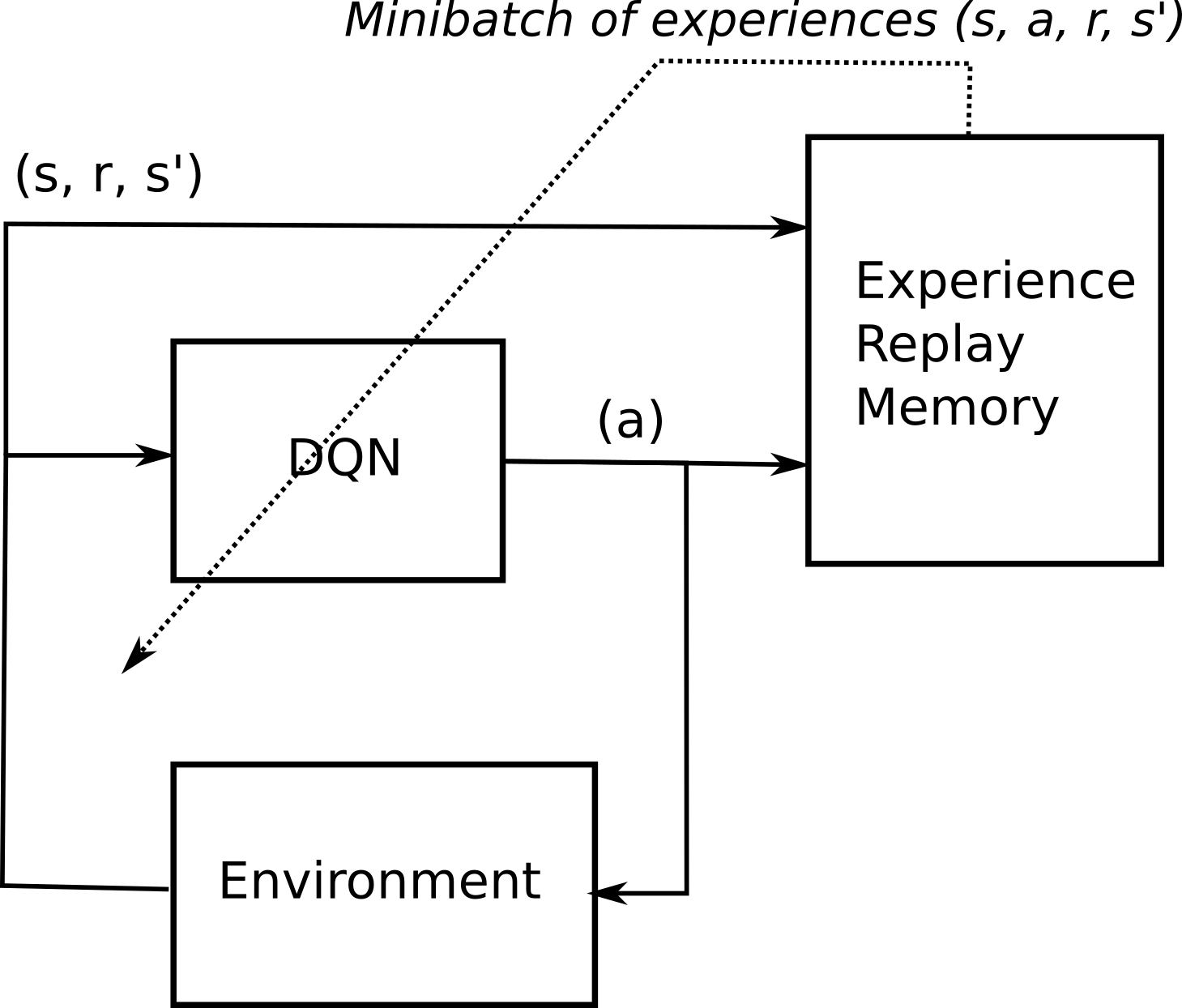
An introduction to Policy Gradients with Doom and Cartpole. ├── Agent.R # Agent class is defined here ├── assets ├── DQN-in-R.Rproj ├── main.R # the main file to run ├── Memory.R # Memory class is defined here (aka Experience Replay Memory) ├── README.md └── train.R # training helper function. An environment which produces a state and reward, and an agent which performs actions in the given environment.
Pseudocode is an informal high-level description of the operating principle of a computer program or an algorithm For example, a print is a function in python to display the content whereas it is System.out.println in case of java , but as pseudocode display/output is the word which covers both the programming languages. Including the full limits (as you have in both your array examples) is good, since it means the reader isn't worrying about whether you start your indices at 0 or 1. Improvements in Deep Q Learning:.
Curiosity-Driven Learning made easy Part I. What is the algorithm of the program that calculates the voltage between the poles of the conductor by using the formula according to the current and. In C++, you get integer division when you divide integers using the ‘/’ symbol.
We use this to construct a new algorithm we call Double DQN. The max operator in standard Q-learning and DQN uses the same values both to select and to evaluate an action.

Deep Reinforcement Learning Of How To Win At Battleship Ccri
Applied Sciences Free Full Text Reinforcement Learning Based Anti Jamming In Networked Uav Radar Systems Html

Reinforcement Learning 6 Temporal Difference Learning
Symmetry Free Full Text Supervised Reinforcement Learning Via Value Function Html

Policy Gradient Algorithms

Active Deep Q Learning With Demonstration Springerlink

Double Q Reinforcement Learning In Tensorflow 2 Adventures In Machine Learning

Deep Reinforcement Learning

Actor Critic Methods A3c And c

Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed Q Targets By Thomas Simonini Freecodecamp Org Medium
Deep Reinforcement Learning Dqn Double Dqn Dueling Dqn Noisy Dqn And Dqn With Prioritized Experience Replay By Parsa Heidary Moghadam Medium

An Overdue Post On Alphastar Part 2

Deep Reinforcement Learning
Deep Reinforcement Learning

Rl Reinforcement Learning Algorithms Quick Overview By Jonathan Hui Medium

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium
Reinforcement Learning And Dqn Learning To Play From Pixels Ruben Fiszel S Website

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

A Trust Aware Task Allocation Method Using Deep Q Learning For Uncertain Mobile Crowdsourcing Springerlink
2

Dqn Ppo Process Summary Programmer Sought

Implementing Deep Reinforcement Learning With Pytorch Deep Q Learning
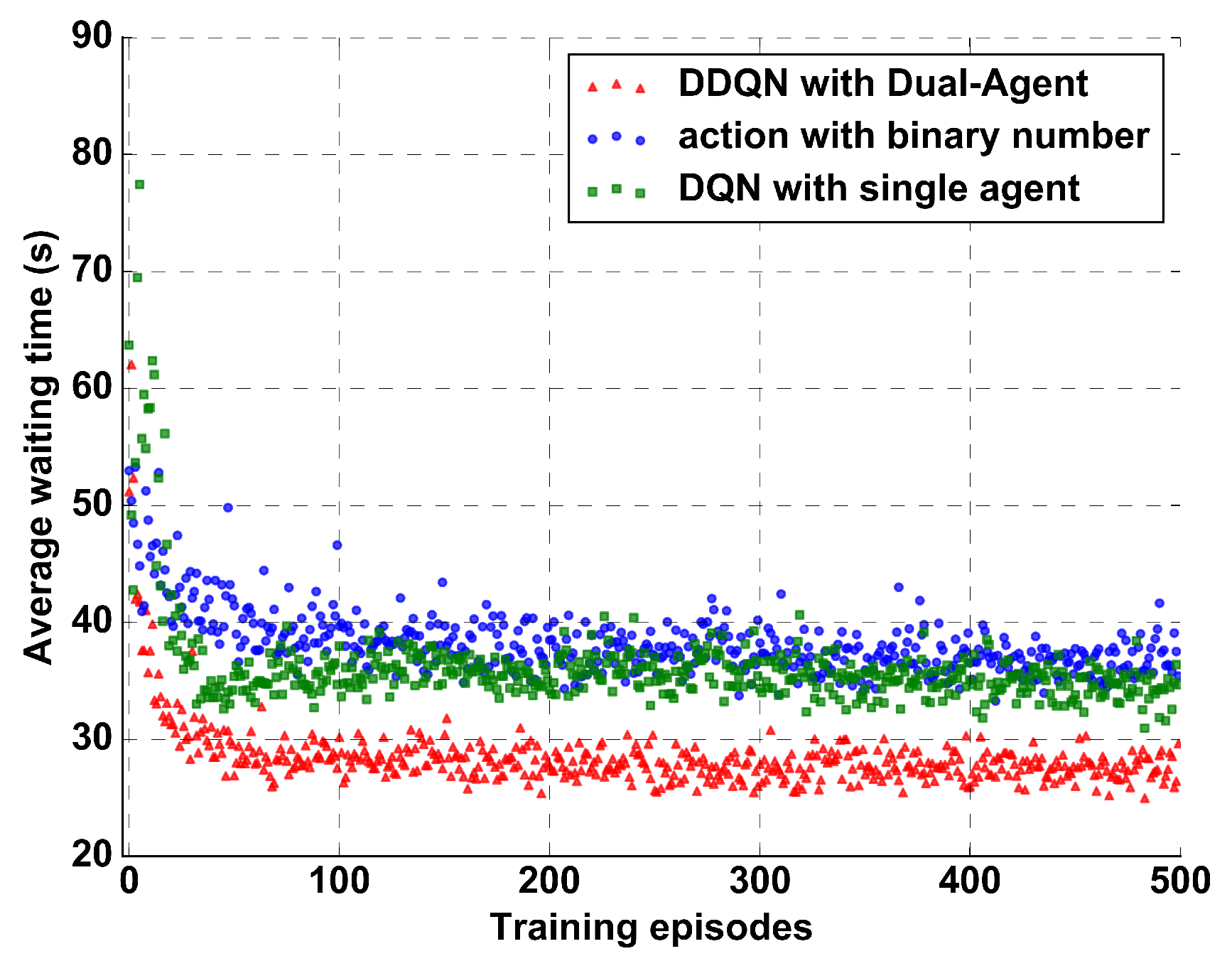
Applied Sciences Free Full Text Double Deep Q Network With A Dual Agent For Traffic Signal Control Html

Reinforcement Learning 6 Temporal Difference Learning

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Twin Delayed Ddpg Spinning Up Documentation

Q Learning Wikipedia
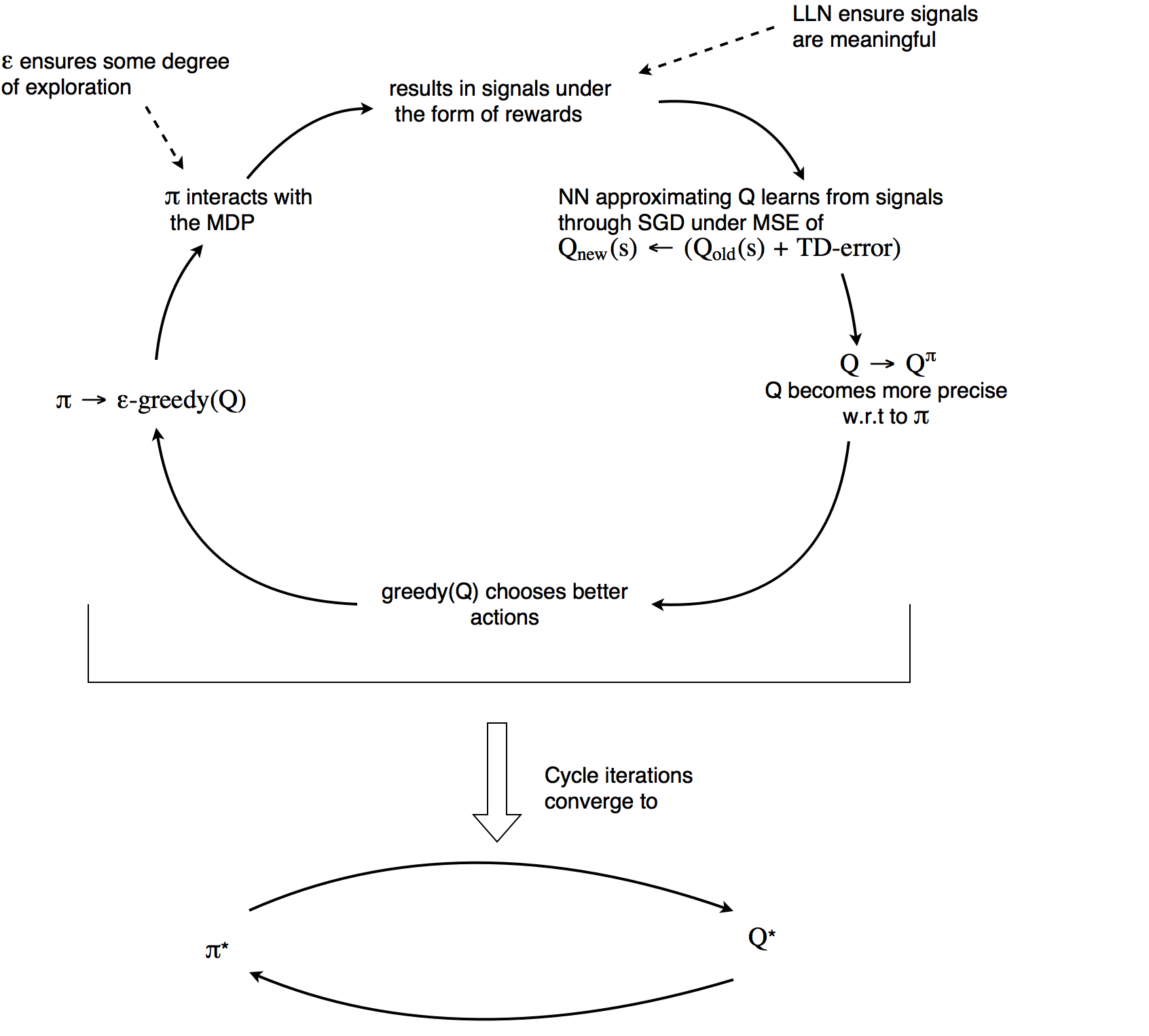
Reinforcement Learning And Dqn Learning To Play From Pixels Ruben Fiszel S Website
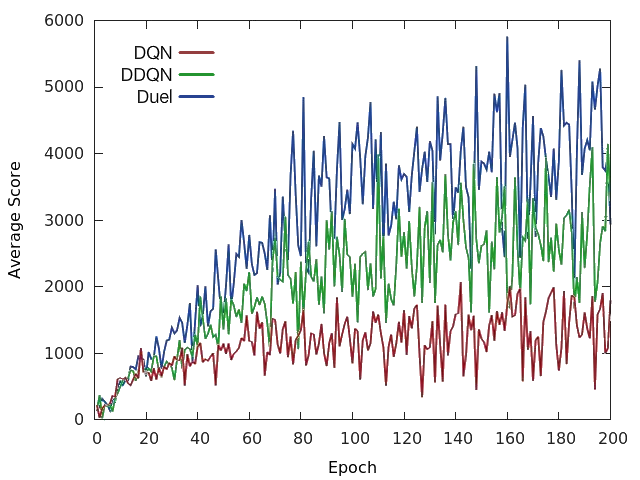
Torch Dueling Deep Q Networks
3

Decomposition Methods With Deep Corrections For Reinforcement Learning Springerlink
Www Csee Umbc Edu Courses Graduate 678 Spring Rl06 Pdf

Pdf Using Deep Q Learning To Understand The Tax Evasion Behavior Of Risk Averse Firms
Q Tbn 3aand9gctv9wou1ce01x5kqcf47vi Fienslmincq8fqjcji4g18goecla Usqp Cau

Policy Gradient Algorithms

Accelerated Deep Reinforcement Learning With Efficient Demonstration Utilization Techniques Springerlink

Deep Deterministic Policy Gradient Spinning Up Documentation

Applications Of Asynchronous Deep Reinforcement Learning Based On Dynamic Updating Weights Springerlink

Q Learning Q Learning Algorithm

Rl Dqn Deep Q Network Can Computers Play Video Games Like A By Jonathan Hui Medium

Policy Gradient Algorithms

Reinforcement Learning For Control Performance Stability And Deep Approximators Sciencedirect

Deep Reinforcement Learning With Hidden Layers On Future States Springerlink

Is A Comparison With Nec2dqn Double Dqn And N Step Dqn N 10 Download Scientific Diagram

Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
Arxiv Org Pdf 1708

Policy Gradient Algorithms

Deep Q Learning Series Dqn Liao Yong Technology Space
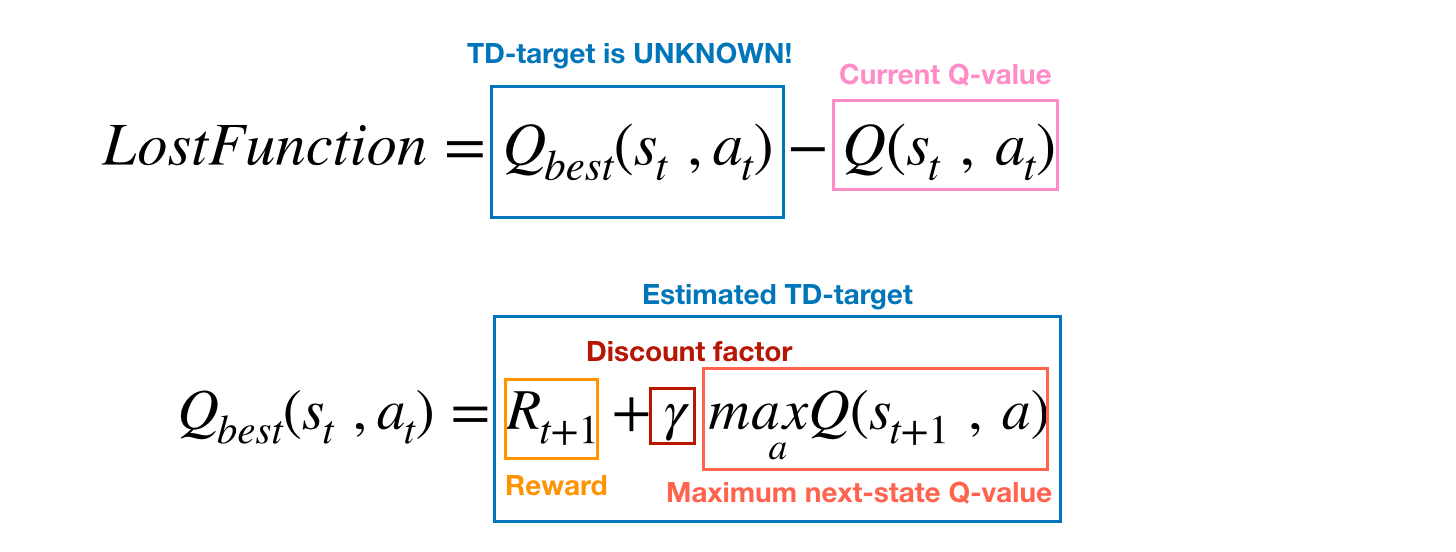
Deep Q Learning Part2 Double Deep Q Network Double Dqn By Amber Medium

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science

Diving Deeper Into Reinforcement Learning With Q Learning

Tic Tac Toe With Tabular Q Learning

Deep Q Learning Part2 Double Deep Q Network Double Dqn By Amber Medium
Reinforcement Learning And Dqn Learning To Play From Pixels Ruben Fiszel S Website
Deep Q Learning An Introduction To Deep Reinforcement Learning

Deep Reinforcement Learning For Supply Chain And Price Optimization

Deep Reinforcement One Shot Learning For Artificially Intelligent Classification In Expert Aided Systems Sciencedirect

Soft Actor Critic Spinning Up Documentation

Deep Reinforcement Learning In Strategic Board Game Environments Springerlink

Review Double Dqn Qiita
Arxiv Org Pdf 1710
Q Tbn 3aand9gctyjenhhqro05br3k9fqk0yiptj48mmfyjrvkp4z4jj5aq9qkyb Usqp Cau

Let S Make A Dqn Double Learning And Prioritized Experience Replay ヤロミル

Decentralized Network Level Adaptive Signal Control By Multi Agent Deep Reinforcement Learning Sciencedirect
Deep Q Learning An Introduction To Deep Reinforcement Learning
Let S Make A Dqn Double Learning And Prioritized Experience Replay ヤロミル

Policy Gradient Algorithms

Reinforcement Learning Algorithms

Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed
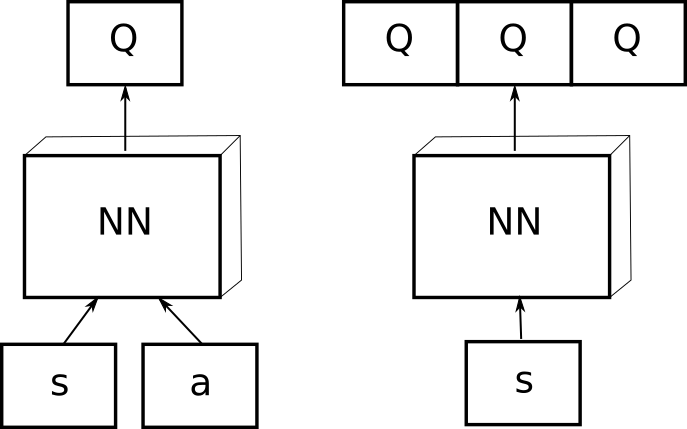
Deep Reinforcement Learning

Gym Experiments Cartpole With Dqn Voyage In Tech
Http Cs231n Stanford Edu Reports 17 Pdfs 616 Pdf

Deep Q Learning Part2 Double Deep Q Network Double Dqn By Amber Medium

Double Q Reinforcement Learning In Tensorflow 2 Adventures In Machine Learning

Accelerated Deep Reinforcement Learning With Efficient Demonstration Utilization Techniques Springerlink

Introduction To Various Reinforcement Learning Algorithms Part I Q Learning Sarsa Dqn Ddpg By Kung Hsiang Huang Steeve Towards Data Science
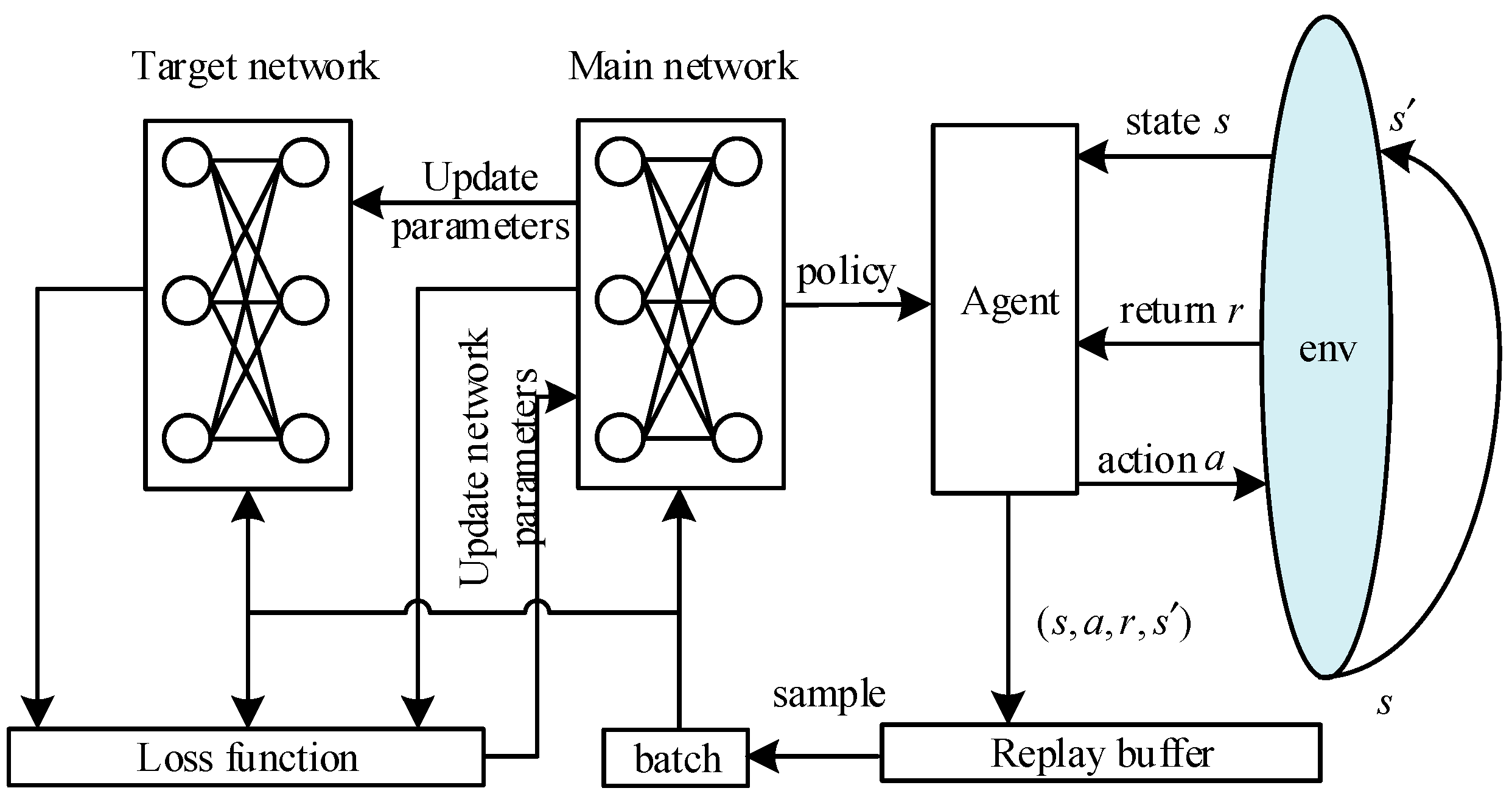
Symmetry Free Full Text Supervised Reinforcement Learning Via Value Function Html

Asynchronous Deep Reinforcement Learning From Pixels Dmitry Bobrenko S Blog

Double Dqn Reinforcement Learning Coach 0 12 0 Documentation

Dqn Qqdn And Dueling Dqn Formula Derivation Analysis Programmer Sought

Distributional Bellman And The C51 Algorithm Felix Yu

Sample Efficient Model Free Reinforcement Learning With Off Policy Critics Springerlink
Diving Deeper Into Reinforcement Learning With Q Learning By Thomas Simonini Freecodecamp Org Medium

Abracadabra

Deep Q Learning This Article Will Be A Introductory By Sandeep Anand Medium

Policy Gradient Algorithms

Reinforcement Learning 6 Temporal Difference Learning

Deep Q Learning Part2 Double Deep Q Network Double Dqn By Amber Medium
Q Tbn 3aand9gcsycgdllosfhkbyyjeygkwl456j39o0u7byb Fj1wyj Ipkhrje Usqp Cau
People Eecs Berkeley Edu Pabbeel Nips Tutorial Policy Optimization Schulman Abbeel Pdf

Improvements In Deep Q Learning Dueling Double Dqn Prioritized Experience Replay And Fixed Q Targets By Thomas Simonini Freecodecamp Org Medium

Complete Code Hand Held Belt Based Drl Based Automatic Driving Path Planning Algorithm Ai Engineering Theory Programmer Sought

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science

Reinforcement Learning 6 Temporal Difference Learning

Double Deep Q Networks Tackling Maximization Bias In Deep By Chris Yoon Towards Data Science



